■オブジェクトの命名規則
オブジェクト名は以下の命名規則に従う必要があります。
・オブジェクト名は30バイト以下
・使用できる文字は、0~9,A~Z,a~z(日本語環境の場合は漢字,ひらがな,カタカナも使用可)
・使用できる記号は、_,$,#のみ
・オブジェクト名の先頭の文字は、数字,記号以外の文字
・Oracleの予約語は使用できない
この他、同一スキーマ内では重複するオブジェクト名は使用できません。また、アルファベットの大文字と小文字は区別されません。
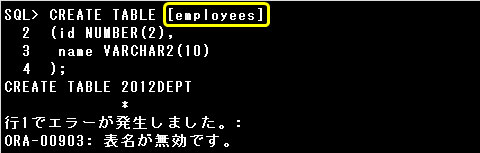
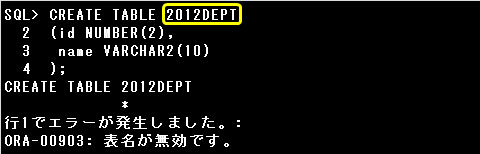
▼エラー例)
・2012DEPT
・[employees]
オブジェクト名の先頭の文字に数字や記号は使用できません。また、”[]”はオブジェクト名に使用できません。
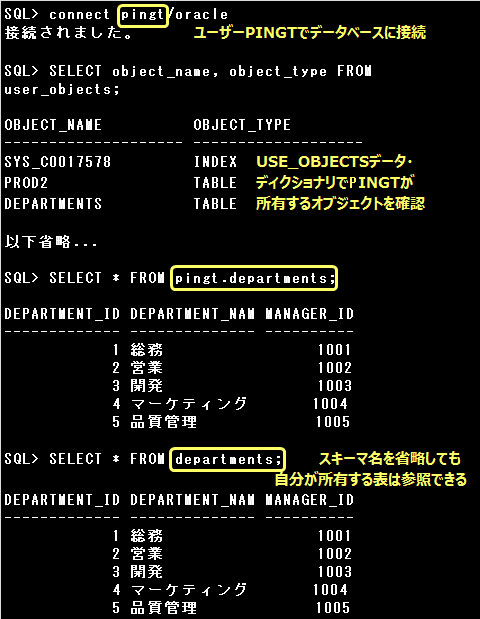
■スキーマ・オブジェクト
データベースに格納できる表やビューなどを総称してデータベース・オブジェクトと言います。
データベース・オブジェクトは必ずいずれかのユーザーに所有されており、スキーマ・オブジェクトとも呼ばれます。
主なスキーマ・オブジェクトは以下のとおりです。

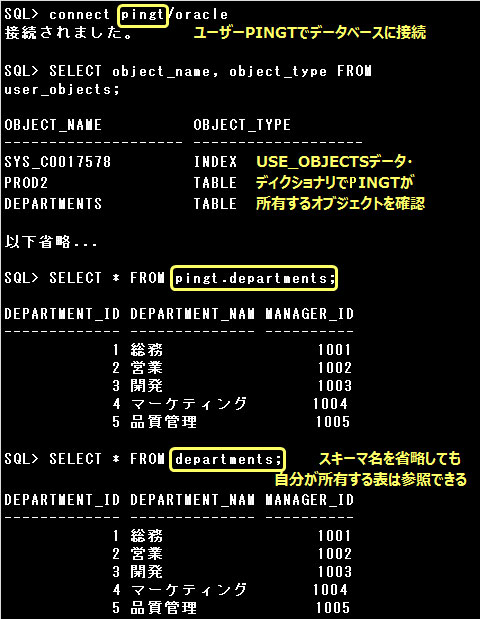
スキーマとは、オブジェクトの所有者を表す論理的な概念です。データベースのユーザーは必ず1つのスキーマを所有し
(スキーマ名はユーザー名と同じ名前になります)、ユーザーが作成したオブジェクトは、そのユーザーが所有するスキーマに格納されます。
ユーザーは別のユーザーが所有しているオブジェクトを参照することもできますが、その場合は、
スキーマ名.オブジェクト名
のように、オブジェクト名の前にスキーマ名をつけて、どのスキーマのオブジェクトを参照するのかを指定しなければなりません。

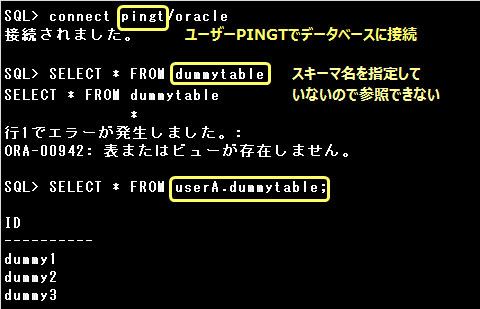
ただし、自分自身が有するオブジェクトを参照する場合には、スキーマ名を省略することができます。
スキーマ名を省略した場合は、ログインしているユーザーのスキーマ内のオブジェクトを参照します。
なお、オブジェクト名は以下の命名規則に従う必要があります。
・オブジェクト名は30バイト以下
・使用できる文字は、0~9,A~Z,a~z(日本語環境の場合は漢字,ひらがな,カタカナも使用可)
・使用できる記号は、_,$,#のみ
・オブジェクト名の先頭の文字は、数字,記号以外の文字
・Oracleの予約語は使用できない
この他、アルファベットの大文字と小文字は区別されません。
また、同一スキーマ内では重複するオブジェクト名は使用できません
(異なるスキーマでは同じオブジェクト名を使用することができます)。
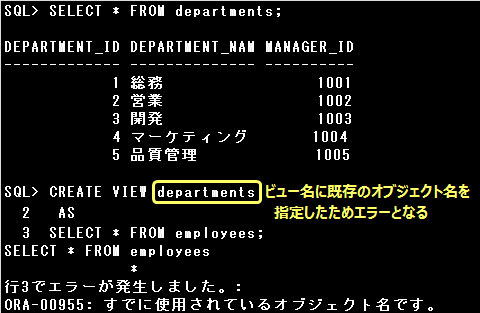

オブジェクト名はスキーマ内で一意である必要があります。そのため、スキーマ内の表やビューに同じ名前を使用することはできません。
ですが、異なるスキーマ同士では同じオブジェクト名を使用することができます。
スキーマ内でオブジェクト名は一意である必要がありますが、異なるスキーマ同士では同じオブジェクト名を使用することができます。
列名はスキーマ・オブジェクトでは無い為、表名と同じ名前を使用することができます。
参考:
データベースに格納できる表やビューなどを総称してデータベース・オブジェクトと言います。
データベース・オブジェクトは必ずいずれかのユーザーに所有されており、スキーマ・オブジェクトとも呼ばれます。
主なスキーマ・オブジェクトは以下のとおりです。

スキーマ・オブジェクトとはデータベースに格納する表やビュー、索引などの総称で特定のユーザーに所有されるものです。
記憶域やロール、ユーザー等システム全体で共有されるものはスキーマ・オブジェクトではありません。
■ALTER TABLEについて
▼例)
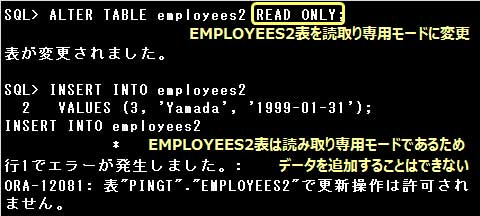
ALTER TABLE employees2 READ ONLY;
設問のSQL文を実行すると、EMPLOYEES2表は読取り専用モードに変更されます。
読取り専用モードの表では、データの追加、更新、削除はできませんが、表の削除は行うことができます。
ALTER TABLE文では、既存の列へデフォルト値を設定できます。
設問の②では、SALARY列のデフォルト値を200000に設定していますが、
この変更が反映されるのはALTER TABLE文の後に挿入される行だけです。
デフォルト値が設定される以前の①で挿入した行のSALARY列はNULL値のまま影響を受けません。
ALTER TABLE文の後の③のINSERT文ではSALARY列が省略されているので、デフォルト値の200000が入ります。
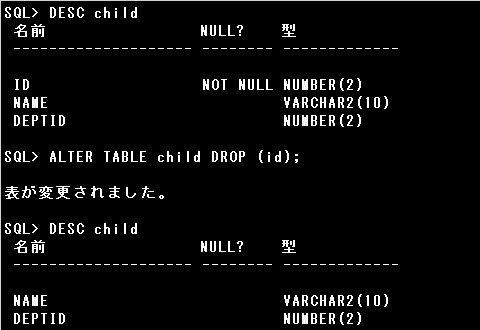
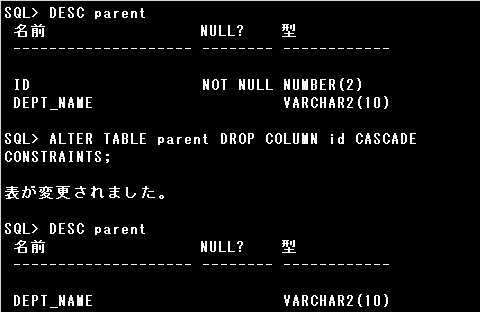
▼ALTER TABLE文で、既存の表の列の削除を行えます。
ALTER TABLE 表名 DROP ( 列名 [, 列名…]) [CASCADE CONSTRAINTS];
※1つの列のみ削除する場合は、次の構文も使用できます。
ALTER TABLE 表名 DROP COLUMN 列名 [CASCADE CONSTRAINTS];
例)
ALTER TABLE child DROP (id);
ALTER TABLE parent DROP COLUMN id CASCADE CONSTRAINTS;
▼列の削除に関しては、以下の注意事項があります。
・削除した列は戻せない
・表には最低1つの列を残す必要がある
・他から参照される参照整合性制約の親表の列はCASCADE CONSTRAINTSオプションを指定する必要がある
・列に多くのデータが含まれている場合は、削除に時間がかかる
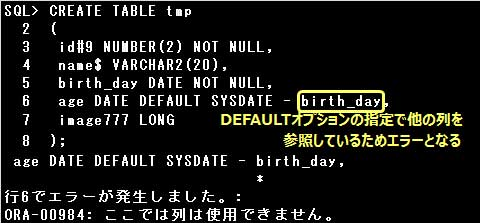
表の作成時に、列にDEFAULTオプションを指定するとその列のデフォルト値を設定できます。
DEFAULTオプションには式や関数を指定できますが、他の列を参照する式は指定できません。
▼既存の表の定義を変更するにはALTER TABLE文を使用します。
ALTER TABLE文では、次の操作を行うことができます。
・新しい列の追加
・既存の列のデータ型の変更
・既存の列へのデフォルト値の設定
・既存の列への制約の定義
・既存の列の削除
・既存の列名の変更
・表のモード変更(読み取り/書き込みモード、読み取り専用モード)
例)テーブル削除の例)次のSQL文でPARENT表とCHILD表を作成しました。
CREATE TABLE parent
(
id NUMBER(2) CONSTRAINT pid_pk PRIMARY KEY,
dept_name VARCHAR2(10)
);
CREATE TABLE child
(
id NUMBER(2) CONSTRAINT cid_pk PRIMARY KEY,
name VARCHAR2(10) CONSTRAINT cname_uq UNIQUE,
deptid NUMBER(2) CONSTRAINT dept_fk REFERENCES parent (id) ON DELETE SET NULL
);
次のSQL文の実行結果として、正しいものはどれですか。
DROP TABLE parent PURGE;
FOREIGN KEY制約の親表として指定された表は、参照されている行がない場合でも削除できなくなります。
親表を削除する場合は、参照している子表を先に削除しなければなりません。
設問では、CHILD表がPARENT表を参照しているので、PARENT表を削除する前にCHILD表を削除しなければなりません。
PARENT表を先に削除するとエラーとなります。
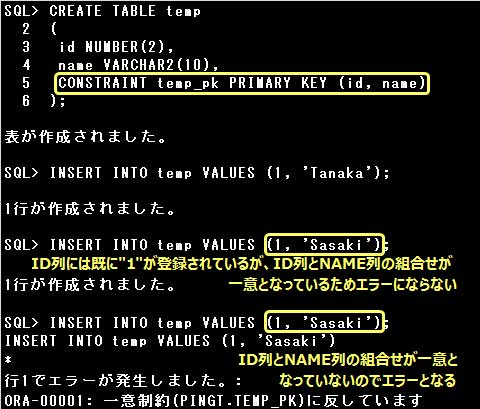
列または列の組合せにUNIQUE制約を定義すると、定義された列または列の組合せに重複したデータを登録することができなくなります。
ただしNULL値は登録することができ、複数の行にNULL値を登録する事もできます。
複数の列の組合せに対してUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。
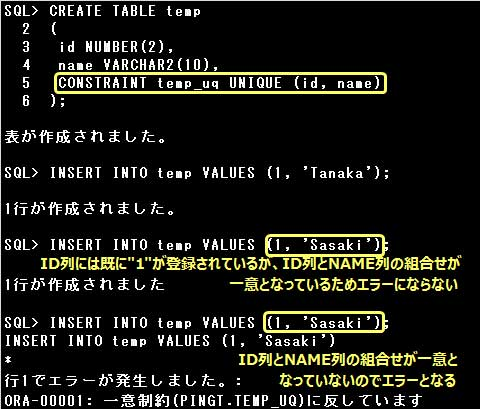
UNIQUE制約を定義すると、自動的に制約と同じ名前の一意索引が作成されます。
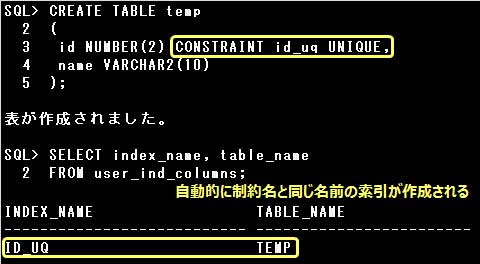
[索引の確認方法]
ログインユーザーが所有する索引(自動的に作成された索引を含む)の情報を調べるには、
USER_IND_COLUMNSデータ・ディクショナリを参照します。
USER_IND_COLUMNSデータ・ディクショナリには索引名や索引を作成した表名、列名などの情報が登録されています。
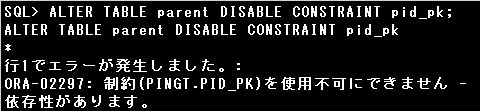
▼設問のPARENT表のID列は、CHILD表のDEPTID列からFOREIGN KEY制約(参照整合性制約とも呼ばれます)の親キーとして
参照されています。
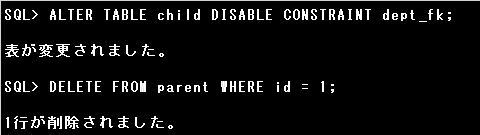
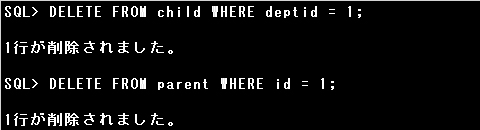
参照する側のデータ、子レコードが存在する場合、親レコードを削除しようとすると設問のエラーが発生します。
先に子レコードを削除するか、FOREIGN KEY制約を無効にすることで、親レコードを削除できるようになります。
もしくは、CHILD表のFOREIGN KEY制約にON DELETEオプションを指定して再作成し、親レコード削除時の処理を設定します。
ALTER TABLE文で既存の表の制約を無効化、もしくは有効化できます。
ALTER TABLE 表名 DISABLE | ENABLE CONSTRAINT 制約名;
例)TBL削除する前に行うSQL
ALTER TABLE child DISABLE CONSTRAINT dept_fk;
DELETE FROM child WHERE deptid = 1;
参照整合性制約の親キーの制約は無効にできません。エラーとなります。
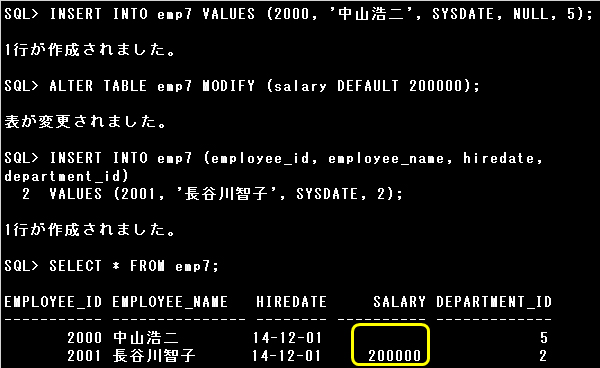
ALTER TABLE文で、既存の列のデータ型、サイズ、デフォルト値を変更できます。
ALTER TABLE 表名 MODIFY ( 列名 [データ型(サイズ)] [DEFAULT 値] [, 列名 …]);
列の変更に関しては、以下のガイドラインがあります。
・列にNULL値のみが格納されている場合、データ型を変更できる
・列にデータが含まれている場合、列の変更後も格納できるデータ型やサイズであれば変更できる
[OK例] CHAR(10) → VARCHAR2(20), VARCHAR2(20)に10バイト以下の文字が格納されている → CHAR(10)
[NG例] CHAR(20)に10バイト以下の文字が格納されている → VARCHAR2(10)
※CHAR型は固定長のため「10バイト以下の文字 + 空白 = 20バイト」で格納される
・デフォルト値の変更は、新しい行の挿入時に反映される
PROD3表のSTATUS列はVARCHAR2(20)ですが、可変長なので実際のサイズは格納されている「FOR SALE」分の8バイトです。
8バイト以上のサイズであればVARCHAR2型とCHAR型のどちらにも変更できます。
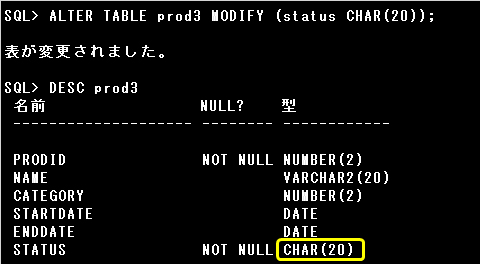
データ型を変更できるのは、列にNULL値のみが格納されている場合です。例)VARCHAR2(20) >>> NUMBER(30)など
既存のデータより小さいサイズには縮小できません。例)VARCHAR2(20) >>> VARCHAR2(5)
ALTER TABLE文で既存の表の列を削除できますが、列の削除中は表にロックがかかり、
列に多くのデータが含まれている場合は削除に時間がかかります。
多くのユーザーがデータベースを利用する時間帯に負荷の高い削除処理を行いたくない場合、
削除したい列にUNUSEDマークを設定して未使用にできます。
ALTER TABLE 表名 SET UNUSED ( 列名 [, 列名…]) [CASCADE CONSTRAINTS];
※1つの列のみUNUSEDにする場合は、次の構文も使用できます。
ALTER TABLE 表名 SET UNUSED COLUMN 列名 [CASCADE CONSTRAINTS];
UNUSEDに設定した列は、次のALTER TABLE文で削除します。データベースの負荷の低い時間帯に行えます。
ALTER TABLE 表名 DROP UNUSED COLUMNS;
SET UNUSED句に関しては、以下の注意事項があります。
・UNUSEDに設定した列は戻せず、DESCRIBEコマンドなどで列名やデータ型を確認できなくなる
・UNUSEDにした列に作成された索引や制約は削除される
・UNUSEDにした列と同じ名前の列を表に追加できる
・UNUSEDにした列の表名と列数は「USER_UNUSED_COL_TABS」ディクショナリで確認できる
・表に対して作成したシノニムの再作成は必要ない
・UNUSEDにした列を含むビューは無効になる

UNUSED操作は取消しできません。
UNUSEDに設定した列は削除した列と同じ扱いになるので、SET UNUSED句を実行した直後から同じ名前の列を表に追加できます。
表に対して作成したシノニムには、再作成することなく正常にアクセスできます。
▼ALTER TABLE文では、既存の列へ制約を定義できます。
※新しく作成したテーブルで、データはまだ未入力状態で、下記のコードを正しく実行できる。
・ALTER TABLE emp7 ADD CONSTRAINT pk_empid PRIMARY KEY (employee_id);
employee_id列にPRIMARY KEY制約を追加しています。
・ALTER TABLE emp7 MODIFY salary CONSTRAINT nn_sal NOT NULL;
MODIFY句でsalary列にNOT NULL制約を追加しています。
・ALTER TABLE emp7 MODIFY (hiredate DEFAULT SYSDATE);
MODIFY句でhiredate列のデフォルト値をSYSDATEに変更しています。
▼エラー例) ※新しく作成したテーブルで、データはまだ未入力状態で、下記のコードは、エラーとなる。
・ALTER TABLE emp7 ADD CONSTRAINT fk_dept FOREIGN KEY (department_id);
department_id列にFOREIGN KEY制約を追加しようとしていますが、REFERENCES句で参照先の表と列が指定されていないためエラーとなります。
▼エラー例) ※新しく作成したテーブルで、データはまだ未入力状態で、下記のコードは、エラーとなる。
・ALTER TABLE emp7 ADD CONSTRAINT nn_sal NOT NULL(salary);
NOT NULL制約はALTER TABLE 文のADD CONSTRAINT句では追加できないためエラーとなります。
誤ったSQL文です。NOT NULL制約はMODIFY句で追加する必要があります。
■データ型
▼LONG型は最大2GBまでの文字データを格納できる可変長のデータ型ですが、次のような制約があります。
・LONG型の列は1つの表に1つだけ定義できる
・LONG型の列には制約は定義できない(NULLおよびNOT NULL制約を除く)
・LONG型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG型の列はコピーできない
・CHAR(5)に「abc」を入力すると、スペースを加え「abc 」が格納される
・LONG型の列には、NULLおよびNOT NULL以外の制約を定義できない
BFILE型は4GBまでにバイナリデータを格納できますが、読取り専用のデータ型ですので、値の変更はできません。
バイナリデータを扱う主なデータ型は次の通りです。

例)NUMBER(10,3)に123.4567を入力すると小数点第4位が四捨五入され、123.457が格納されます。
VARCHAR2型のデータサイズの指定は省略できません。
▼Oracle Databaseには、多くの組込みデータ型が用意されています。
・BFILE型 : OS上のバイナリファイルのポインタ情報のみを格納する
BFILE型は最大4GBまでのバイナリデータを格納できる、読み取り専用のデータ型です。
データはOracleのデータファイル内ではなく、OS上にバイナリファイル(動画やイメージ)として格納され、
ファイルに対するポインタ情報のみが格納されます。
CLOB型は最大4GBまでの文字データを格納できます。2GBまでの文字データを格納できるのはLONG型です。
INTERVAL YEAR TO MONTH型は、期間を年、月の単位で格納します。
期間を日、時、分、秒の単位で格納するのはINTERVAL DAY TO SECOND型です。
NUMBER型には正と負の数値を格納できます。
RAW型は最大2000バイトまでのバイナリデータを格納できる、可変長のデータ型です。
列にROWIDを格納するためのデータ型はROWID型です。
▼期間を格納するデータ型には、
・INTERVAL YEAR TO MONTH:期間を年、月の単位で格納する
・INTERVAL DAY TO SECOND:期間を日、時、分、秒の単位で格納する
があります。
設問で最長の貸出可能期間は20日ということですので、
日の単位で期間を格納できるINTERVAL DAY TO SECOND型の変数を定義すれば良いことがわかります。
なお、INTERVAL YEAR TO MONTH型、INTERVAL DAY TO SECOND型はともにDATE型との演算が可能です。
▼LONG型の列には以下の制限があります。
・LONG型の列は1つの表に1つだけ定義できる
・LONG型の列には制約は定義できない(NULLおよびNOT NULL制約を除く)
・LONG型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG型の列はコピーできない
▼バイナリデータを扱う主なデータ型は次の通りです。

▼LONG RAW型はLONG型と同様に以下の制限があります。
・LONG RAW型の列は1つの表に1つだけ定義できる
・LONG RAW型の列には制約は定義できない
・LONG RAW型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG RAW型の列はコピーできない
▼期間リテラルの書式
期間を表す値を記述するには、期間リテラルの書式に基いて記述します。
設問のINTERVAL ‘200’ MONTHは200ヶ月間の意味なので、16年8ヶ月を表すINTERVAL ’16-8’ YEAR TO MONTHと同義です。
なお、期間データ型には書式モデルはありません。SELECT文で期間データ型を表示させると、
INTERVAL ’16-8’ YEAR TO MONTH は +16-8
INTERVAL ’50-11′ YEAR TO MONTH は +50-11
INTERVAL ‘4 12:30:10.1234567’ DAY TO SECOND は +04 12:30:10.123457
のように表示されます。

▼NUMBER型の正数と小数点
NUMBER型の値を定義する際、全体の桁数と位取りを指定します。
位取りは小数点以下の桁数のことで、全体の桁数のうち小数点以下の桁数がいくつであるかを指定します。
位取りに負の値が指定された場合は、整数部の丸める桁数を指定したとこになります。
また、全体の桁数と位取りの両方が省略された場合は、最大精度の浮動小数点となります。
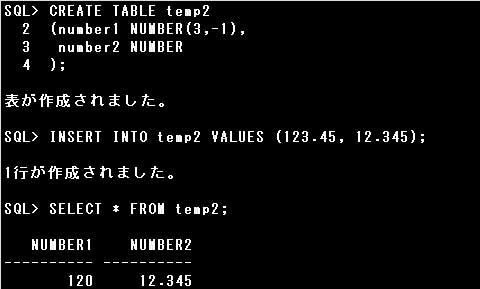
例)
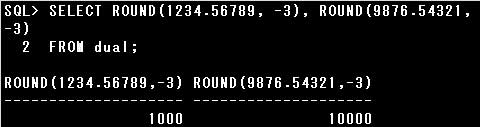
・データ型がNUMBER(3,-1)の列に123.45を入力すると、120が格納される
・データ型がNUMBERの列に12.345を入力すると、12.345が格納される
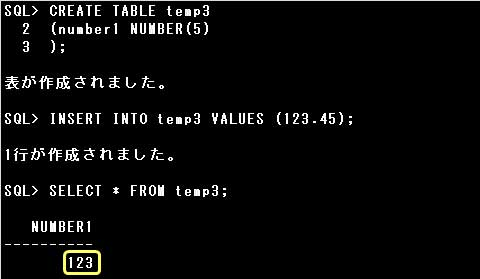
位取りが省略されているので、少数点第1位で四捨五入され、123が格納されます。
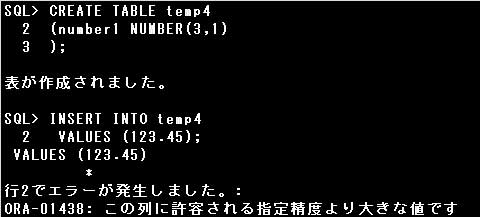
位取りに-2が指定されているので、十の位が四捨五入され、100が格納されます。

参考:
NUMBER型は数値データを格納するために使用するデータ型です。
次のように定義します。
列名 NUMBER[(最大精度[, 位取り])]
最大精度:格納する数値の全体の桁数(1~38桁)
位取り:小数点以下の桁数(-84~127)。負の値が指定された場合は、整数部の丸める桁数を指定したとこになる。
位取りを省略した場合は、NUMBER(最大桁数, 0)と同じことです。
また、位取りに負の値を設定した場合は、整数部の丸める桁数が指定されたことになります。
最大精度、位取りの両方を省略した場合は、最大精度の浮動小数点となります。

NUMBER(5,2)と定義された列に”123.456″を格納しようとすると、小数点以下第2位のデータに四捨五入され、
123.46が格納されます。
また、NUMBER(5,2)と定義された列に”1234.56″を格納すようとすると、
整数部が4桁となり指定した精度に値を収めることができませんのでエラーとなります。
最大桁数を5桁、小数点以下を2桁としているので、整数部は3桁以内の数値しか格納できません。


▼CHAR型、VARCHAR2型の特徴は次の通りです。
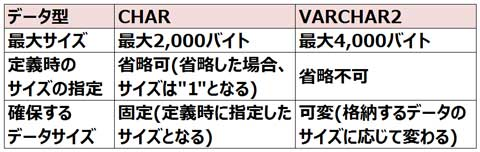
LONG型の列はORDER BY句やGROUP BY句に指定することはできません。
LONG型が2GBまでなのに対し、CLOB型は4GBまで扱うことができます。
LONG型は1つの表に1つだけ定義することができます。
▼TIMESTAMP型
TIMESTAMP型はDATE型を拡張したデータ型で、世紀、年、月、日、時、分、秒に加え秒の小数点以下の値を格納することができます。
TIMESTAMP型の列に値を格納するためには、日付リテラルを使用するか、文字列や数値をTO_TIMESTAMP関数でTIMESTAMP型の値に変換し
TO_TIMESTAMP関数で文字列からTIMESTAMP型への変換ができます。
暗黙的データ変換により、TIMESTAMP型の値をDATE型の列へ格納することができます。
IMESTAMP型には年、月、日のほか、時、分、秒、秒の小数点以下の値を格納することができます。
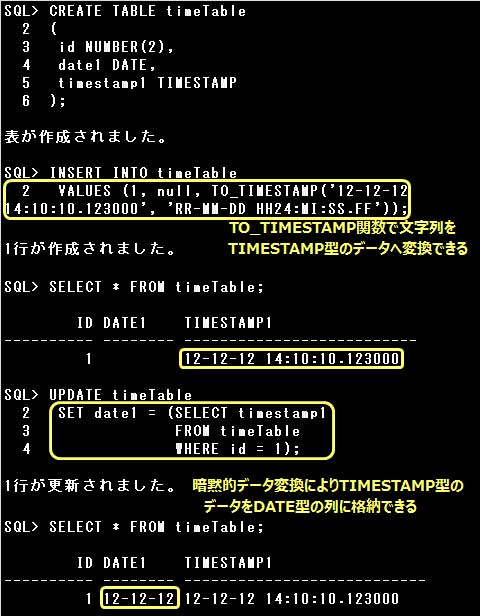
▼ROWID型
ROWID型は、行の一意なアドレスであるROWID疑似列(実際には列として定義されていない列)から返される値を列に
格納するために使用する、BASE64文字列のデータ型です。
行の一意なアドレスを表すBASE64文字列
表にはROWID列の定義はありませんが、SELECT句にROWID疑似列を指定すると、各行の一意なアドレスを確認できます。
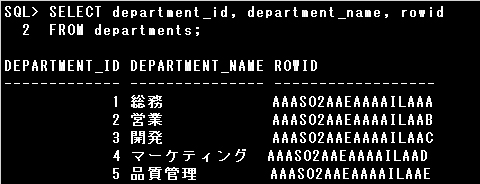
ROWID型を2つ以上指定した表を作成できます。
データ型がNUMBER(5,2)の列に12.345を入力すると、小数点第3位が四捨五入され、12.35が格納されます。

■DROP TABLE
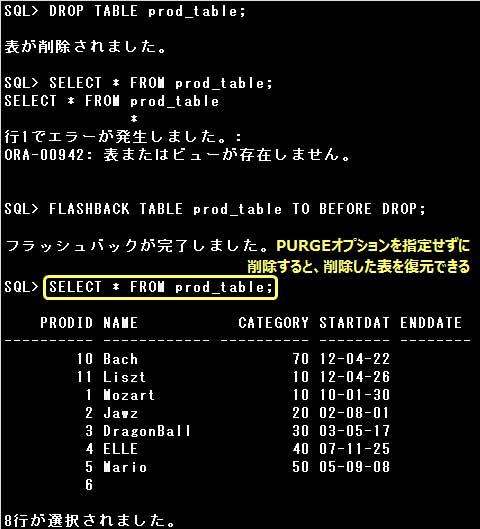
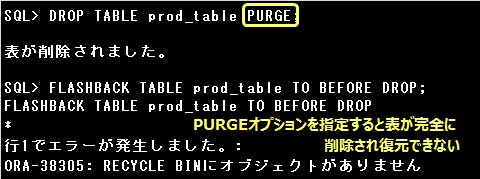
表を完全に削除するには、DROP TABLE文にPURGEオプションを指定して実行します。
PURGEオプションを指定しないと、表はごみ箱に移動され、後で復元することができます
▼表のデータだけを削除します。
・TRUNCATE TABLE 表名;
・DELETE FROM 表名;
▼表をごみ箱へ移動します。ごみ箱へ移動した表はFLASHBACK TABLE文で復元することができます。
・DROP TABLE 表名;
表の削除はDROP ANY TABLE権限を持つユーザーによって行われます。
DROP TABLE 表名 [PURGE];

表を削除すると、表と表内のデータ、表に定義した制約、索引も同時に削除されます。
その表を参照しているビューやシノニムは削除されませんが、無効になります。無効になったビューやシノニムにアクセスするとエラーになります。

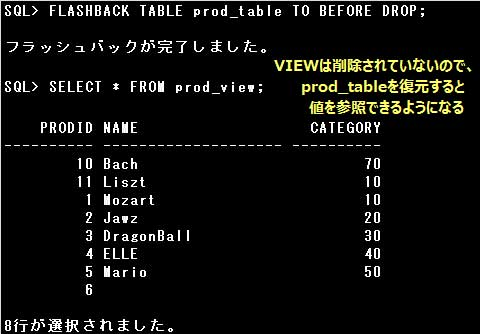
PURGEオプションを付けずに表を削除すると、表はごみ箱に移動するだけで、完全に削除されるわけではありません。
完全に削除するにはPURGEオプションを指定して表を削除します。
DROP TABLE文はDDL文に該当します。
DDL文では、1文で1つのトランザクションとなるため、DROP TABLE文実行後はトランザクションが終了します。
DROP TABLE文では、表の構造、データの両方が削除されます。表のデータだけを削除したい場合はDELETE文を使用します。
DROP TABLE文にPURGEオプションが指定されていない場合、表はごみ箱に移動するだけで、完全に削除されたわけではありません。
FLASHBACK TABLE文でごみ箱に移動した表を復元することができます。
表を削除してもビューは削除されません。
■PRIMARY KEY制約
PRIMARY KEY制約を定義すると、定義された列または列の組合せに重複したデータやNULL値を登録することができなくなります。
PRIMARY KEY制約は1つの表に1つしか定義することができません。ですが、必ず指定しなければならないわけではありません。
PRIMARY KEY制約は複数の列の組合せに対して定義することができます。その場合は表レベルで定義します。
なお、PRIMARY KEY制約を定義すると、自動的に制約と同じ名前の一意索引が作成されます。

PRIMARY KEY制約は1つの表に1つだけ定義することができます。複数の列に個別にPRIMARY KEY制約を定義することはできません。

複数の列の組合せに対してPRIMARY KEY制約を定義する場合は、表レベルで定義します。
PRIMARY KEY制約を定義すると、自動的に制約と同じ名前の一意索引が作成されます。

[索引の確認方法]
ログインユーザーが所有する索引(自動的に作成された索引を含む)の情報を調べるには、
USER_IND_COLUMNSデータ・ディクショナリを参照します。
USER_IND_COLUMNSデータ・ディクショナリには索引名や索引を作成した表名、列名などの情報が登録されています。
■FOREIGN KEY制約
PARENT表はCHILD表のFOREIGN KEY制約(参照整合性制約とも呼ばれます)の親表として参照されています。
この場合、参照されている行がない場合でも、子表よりも先に親表を削除できません。DROP TABLE文はエラーとなります。
しかしデータの削除に関しては、FOREIGN KEY制約にON DELETEオプションを指定することによって、
親表の行を削除した場合に子表の行をどのようにするかを指定できます。
▼例)
CREATE TABLE parent
(
id NUMBER(2) CONSTRAINT pid_pk PRIMARY KEY,
dept_name VARCHAR2(10)
);
CREATE TABLE child
(
id NUMBER(2) CONSTRAINT cid_pk PRIMARY KEY,
name VARCHAR2(10) CONSTRAINT cname_uq UNIQUE,
deptid NUMBER(2) CONSTRAINT dept_fk REFERENCES parent (id) ON DELETE CASCADE
);
INSERT INTO parent VALUES (1, ‘parent’);
INSERT INTO child VALUES (10, ‘child’, 1);
FOREIGN KEY制約で参照されている親表は子表よりも先に削除できません。
データが存在した場合は、FOREIGN KEY制約の親表を切り捨てることはできません。
FOREIGN KEY制約に「ON DELETE CASCADE」が指定されているので、DELETE文は正常に実行できます。
■正規形について


設問の表は、商品ID、商品名、単価、数量、金額の同じ内容の列が繰り返し現れて非常に大きな表になっています。
また、「受注前に商品を登録できない」「商品名や価格が変更になったときに同じ商品のデータを全て更新しなければならない」
など、管理がし難く、リレーショナル・データベースに格納できないデータです。
このような正規化されていないデータを非正規形といいます。
正規化では、データの重複を排除し、データ間の正しいリレーションシップを設定してデータを一元管理できるようにします。
・第1正規形
第1正規化は、非正規形の表に次の作業を行います。
・主キーを設定する
・繰り返し現れる列のデータをグループ化して、別の表に切り離す
・導出項目(他の属性から算出できる項目)を削除する
・第2正規形
第2正規化は、第1正規形の表から部分関数従属性であるものを除きます。
・第3正規形
第3正規化は、第2正規形から推移関数従属性を除きます。
■リレーショナル・データベース(RDB)
Oracle Databaseはリレーショナル型およびオブジェクト・リレーショナル型データベースを管理するためのソフトウェアです。
リレーショナル・データベース管理システム(RDBMS)、
またオブジェクト・リレーショナル・データベース管理システム(ORDBMS)とも呼ばれます。
リレーショナル・データベース(RDB)には次のような特徴があります。
・データを行と列からなる2次元の表形式で格納する
・関連のあるデータをグループ化し、複数の表に分割して管理する
・関連のある表同士を表に格納されたデータに基づいて関連付けることができる
・E. F. Coddのルール(エドガー・F・コッドによって考案されたRDBMSに関する規則)をサポートする
・SQLを使用してデータにアクセスする
■オブジェクト指向データベース(OODB)モデル
Oracle Databaseはリレーショナル型およびオブジェクト・リレーショナル型データベースを管理するためのソフトウェアです。
リレーショナル・データベース管理システム(RDBMS)、またオブジェクト・リレーショナル・データベース管理システム(ORDBMS)とも呼ばれます。
オブジェクト・リレーショナル型データベースは、オブジェクト指向データベース(OODB)とも呼びます。次の特徴があります。
・リレーショナル型データベースの機能を拡張し、完全な互換性を持つ
・データ構造が定義されたメソッドが組み込まれている
・同じデータベースで複数のオブジェクトをサポートする
■階層型データベース
・ツリー構造でデータを格納する
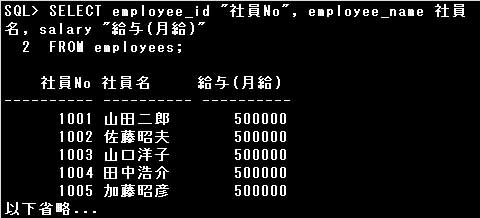
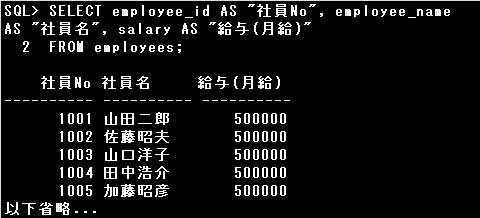
■ASキーワード
例)
SELECT employee_id “社員No”, employee_name 社員名, salary “給与(月給)” FROM employees;
SELECT employee_id AS “社員No”, employee_name AS “社員名”, salary AS “給与(月給)” FROM employees;
SQL文の実行結果に表示される列見出しを変更したい場合は、SELECT句に列別名を指定します。
列別名は項目名と列別名をスペースで区切るか、明示的にASキーワードで指定します。
列別名はオブジェクトのネーミング規則に従って命名されますが、大文字と小文字を区別したり、
ネーミング規則に反する列別名(スペースを使用するなど)を使用する場合は、列別名を二重引用符(“)で囲まなければなりません。
設問の問合せ結果の列見出しのうち、「社員No」では大文字と小文字が使用されており、
「給与(年収)」では記号が使用されていますので、この2つの列見出しは列別名を”(二重引用符)で囲んで指定したことがわかります。
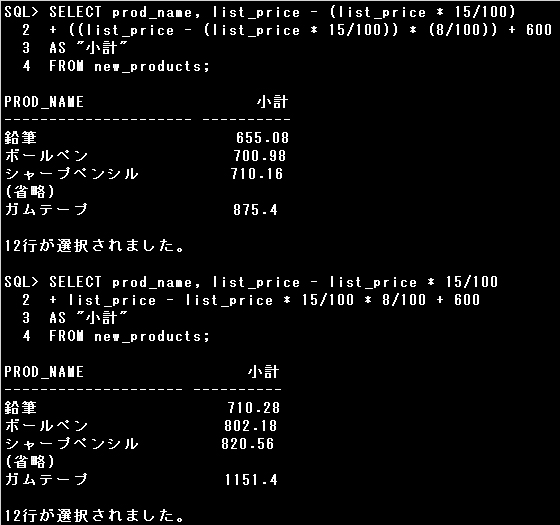
■算術演算子
算術式の優先順位を変更したい場合は、()括弧で囲むことで優先順位が高くなります。
設問のSQL文の算術式を確認してみましょう。分かりやすいようにlist_priceに100を割り当てて計算します。
[括弧あり] 100 – (100 * 15/100) + ((100 – (100 * 15/100)) * (8/100)) + 600 = 691.8
85 85 0.08
[括弧無し] 100 – 100 * 15/100 + 100 – 100 * 15/100 * 8/100 + 600 = 783.8
100-0.15+100-1.2+600
演算子の優先順位に従って計算すると、括弧無しの方が価格が高い結果となりました。
100 – (100 * 15/100) 85
■算術式
算術式はSELECT句だけではなく、FROM句を除く任意の句で使用できます。
・SELECT句 : データベースから取り出すデータを選択します
・FROM句 : データベースのどの表からデータを取り出すかを決定します
・WHERE句 : 条件に従って取り出すデータを制限します
・GROUP BY句 : 取り出すデータをグループ化します
・HAVING句 : 条件に従って取り出すグループを制限します
・ORDER BY句 : 取り出したデータをソートします
■WHERE句
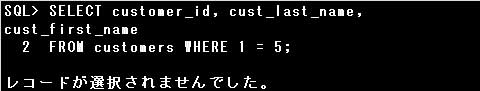
また、条件を次のように変更すると、全ての行が検索されます。
条件1=1が常に成立する(条件が真である)ためです。
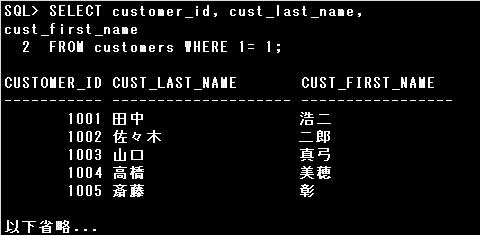
EMPLOYEES表のSALARY列が300000より大きい従業員を検索する条件として、正しいものはどれですか(該当するものを全て選択して下さい)。
設問のように「より大きい」を条件とする場合は、比較演算子の「>」を使用します。
または、条件の判定結果を反転させる「NOT演算子」を使用して、
「NOT salary <= 300000」(salaryが300000以下で無ければ真)とすることもできます。
例)
WHERE NOT salary <= 300000
WHERE salary > 300000
エラー例)
・WHERE NOT salary < 300000
「salaryが300000より小さく無ければ真」となります。
この場合、salaryが300000の場合も真となってしまいます。
・WHERE salary < 300000
「salaryが300000より小さければ真」となります。
・WHERE salary >= 300000
「salaryが300000以上なら真」となります。
この場合、salaryが300000の場合も真となってしまいます。
■ソート ASC DESC ORDER BY句
参考:
SELECT文の検索結果はどのような順番で表示されるか保証されていません。
そのため、何らかの値によってソートされた検索結果が必要な場合はORDER BY句を指定します。
ORDER BY句はWHERE句など他の句と同時に指定できますが、必ずSELECT文の最後に記述する必要があります。
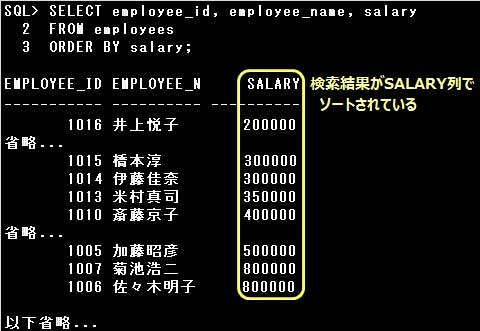
ORDER BY句の項目には「列名」の他、以下を指定できます。どれも重要です。
・列別名(*WHERE句では指定不可)
・算術式
・SELECT句に指定されている項目の順番(数値)
ASCとDESCは昇順/降順を指定するキーワードです。ASCで昇順(小さい順)、DESCで降順(大きい順)にソートします。
省略するとASCが指定されたものとみなされます。
ORDER BY句では複数の項目を指定できますが、ASC/DESCも項目ごとに指定できます。
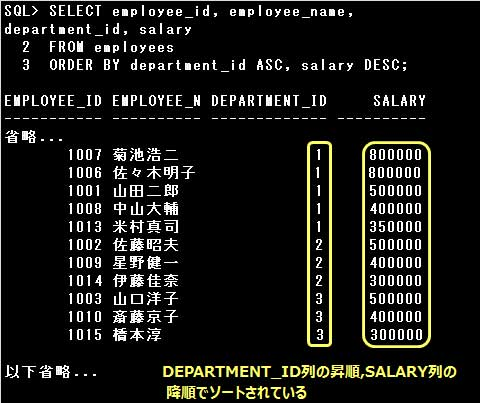
上記の例では、まず「department_id」列で昇順ソート(ASC 省略可)し、
「department_id」が同じ値の行では「salary」列で降順ソート(DESC)しています。
なお、以下の例のように、SELECT句で指定されていない列名をORDER BY句で指定することも可能です。
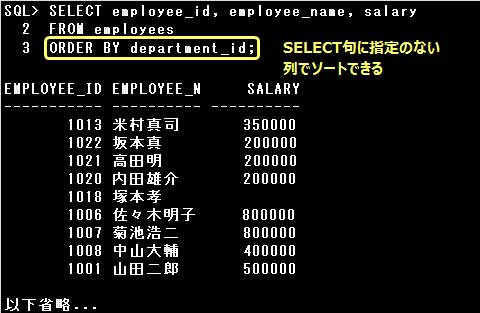
ソートの順序はソートする項目のデータ型によって次のようになります。
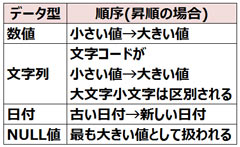
上表のように、NULL値は最も大きい値として扱われます。
そのため、ソート項目にNULL値が含まれる行は、昇順ソートの場合は最後に、降順ソートの場合は先頭に表示されることになります。
そこでORDER BY句では、次のキーワードで、昇順、降順にかかわらずNULL値が含まれる行を先頭もしくは
最後に表示するように指定できます。
ORDER BY 項目 [NULLS FIRST | NULLS LAST]
NULLS FIRSTはソート順にかかわらずNULL値が含まれる行を先頭に表示し、NULLS LASTは最後に表示します。
ORDER BY句では、ソートする項目として、列別名やSELECT句に指定されている順番(数値)を指定できます。
大文字と小文字を区別するためなどに二重引用符(“)で囲んだ列別名を使用している場合は、
ORDER BY句でも同様に列別名を二重引用符(“)で囲む必要があります。
SALARY列はSELECT句で左から3番目に指定されていますので、「ORDER BY 3」とすれば SALARY列でソートされます。
また、月収の多い順に表示するには、降順でソートする為のDESCキーワードが必要です。
■置換変数
SQL*PlusやSQL Developerなどのツールでは、置換変数を利用できます。
置換変数を利用すると、WHERE句の条件などに指定する値を、SQL文の中に直接記述するのではなく、
実行時に値を指定できるようになります。
置換変数には「&置換変数」と「&&置換変数」の2種類があり、「&置換変数」はSQL文実行後に変数の値が破棄されますが、
「&&置換変数」はセッションを切断するまで値が保持されます。
なお、置換変数はWHERE句だけではなく、SQL文の全ての箇所で使用できます。
■BETWEEN
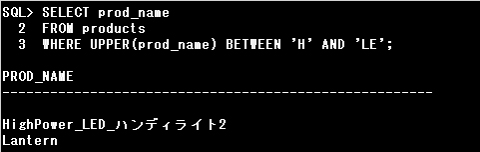
BETWEEN演算子の下限値、上限値に文字リテラルが指定された場合は、指定された文字列の文字コードの範囲で検索が行われます。
設問の場合は、UPPER(prod_name)で全て大文字に変換された商品名の頭文字が「H」で始まるものから、
「LE」という2文字の文字コードの範囲までが検索されます。
このSQL文でUPPER関数を使わないと、商品名「Lantern」はヒットしません。
2文字目の小文字の「a」は大文字の全アルファベットより文字コードが大きいからです。
UPPER関数で大文字「LANTERN」にした場合は、最初の2文字「LA」の組合せの文字コードが、
検索の上限値の「LE」より小さいため、設問のように検索でヒットします。
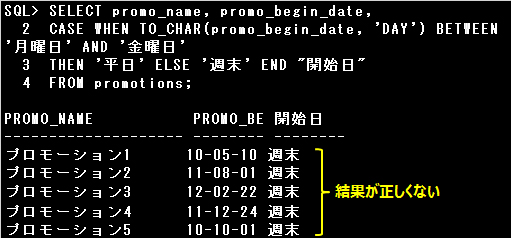
▼エラー例)
・SELECT promo_name, promo_begin_date,
CASE WHEN TO_CHAR(promo_begin_date, ‘DAY’) BETWEEN ‘月曜日’ AND ‘金曜日’
THEN ‘平日’ ELSE ‘週末’ END “開始日”
FROM promotions;
検索CASE式です。BETWEEN演算子に文字列を指定した場合は、文字列の文字コードの範囲で検索が行われます。
単純に曜日の判定はできないので、エラーとはなりませんが正しい結果は得られません。
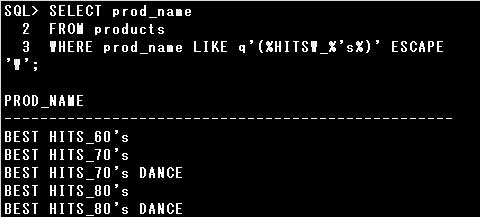
■LIKE演算子
LIKE演算子を使用すると、指定した文字パターンに一致した行を検索できます。
文字パターンには、任意の1文字と一致する「_」や、0文字以上の任意の文字列と一致する「%」といった、
ワイルドカードを利用できます。
ワイルドカードをリテラルの一部として使用する場合は、ESCAPEオプションを指定してワイルドカードを
リテラルとして扱えるようにしなければなりません。
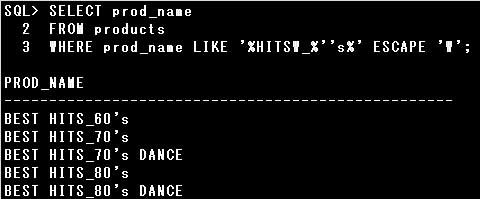
設問では「HITS_」が含まれている行を検索するので、文字パターンは’%HITS_%’となりますが、
文字パターンに”_”が含まれているので、ESCAPEオプションを指定して「_」をリテラルとして扱う必要があります。
さらに「’S」も含まれるようにしなければなりませんが、一重引用符(‘)が含まれているので、
代替引用符q演算子を使用するか、一重引用符(‘)を2つ記述して一重引用符(‘)をリテラルとします。
▼正しい例)
WHERE prod_name LIKE q'(%HITSW_%’s%)’ ESCAPE ‘W’
WHERE prod_name LIKE ‘%HITSW_%”s%’ ESCAPE ‘W’
ここではエスケープ文字として「W」を指定していますので、「W」の直後のワイルドカードは通常のリテラルとして扱われます。
設問のSQL文は、指定された条件により、DEPARTMENT_ID列の値が1,3,5以外の行が取り出されます。
これは、DEPARTMENT_ID列の値が1以外 かつ 3以外 かつ 5以外ということですので、
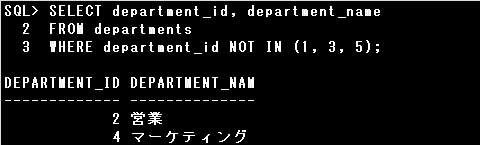
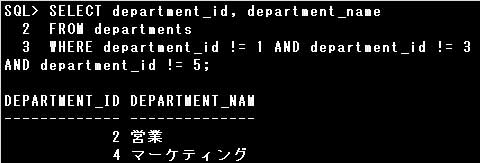
AND演算子を使用して次のように置き換えることができます。
参考:
IN演算子を使用すると、リストに指定した複数の値のいずれかと一致する行を検索できます。
IN演算子の指定方法は次のとおりです。
WHERE 項目名 IN (値1[, 値2, …])
OR演算子で複数の条件を指定している場合には、IN演算子で置き換えることができます。
WHERE department_id = 1
OR department_id = 2
OR department_id = 3
上記の条件をIN演算子で置き換えると、
WHERE department_id IN (1, 2, 3)
となり、OR演算子で複数の条件を指定するよりもわかりやすくなります。
ただし、IN演算子は、SQL文の実行時に内部的にOR演算子による条件のセットとして処理されるため、
実行時のパフォーマンスの違いはありません。
また、IN演算子をNOT演算子と組み合わせると、IN演算子のリストに指定した値以外という条件を作成することができます。
WHERE 項目名 NOT IN (値1[, 値2, …])
例えば以下のようにすると、department_idの値が1,2,3以外、という条件になります。
WHERE department_id NOT IN (1, 2, 3)
これは以下の条件と同じです。
WHERE department_id != 1
AND department_id != 2
AND department_id != 3
「a か b のいずれかでない」という条件は以下のように変換できます。
NOT(a OR b) = (NOT a) AND (NOT b)
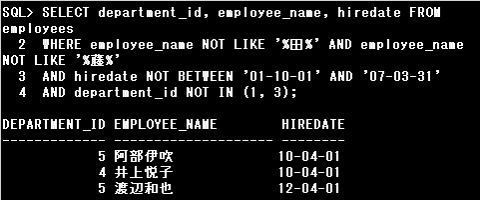
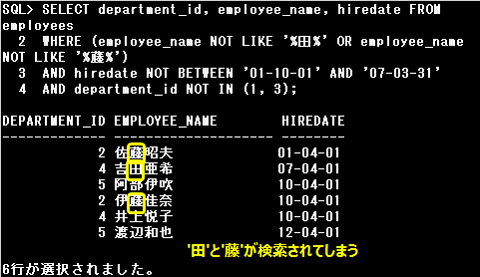
条件1の中で2つのNOT LIKEがOR演算子で結ばれているため、以下のように解析されます。
(NOT a) OR (NOT b) = NOT(a AND b)
すなわち[「田」と「藤」の両方が含まれていない]条件となるので、希望の結果は得られません。
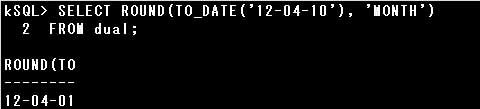
■ROUND関数
ROUND関数は、引数で指定された日付値を丸めて返します。
設問のROUND関数では書式に「DD」が指定されています。
「DD」は指定した日付が正午より前なら当日の午前0時を、正午以降なら翌日の午前0字を返します。
■TRIM関数
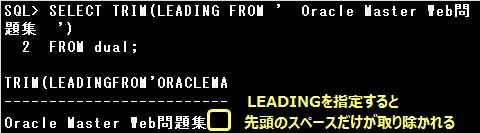
TRIM関数は、引数で指定された文字列の前後にある削除文字を取り除いた文字列を返す関数です。
設問では先頭のスペースを削除するので、削除位置に”LEADING”を指定します。
また、スペースを削除する場合は削除文字の指定は必要としません。


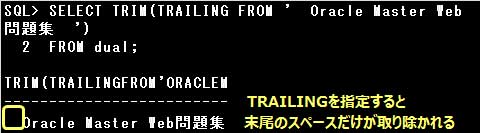
TRIM関数は、引数で指定された文字列の前後にある削除文字を取り除いた文字列を返します。
TRIM([LEADING | TRAILING | BOTH] [削除文字] FROM 文字列)
または
TRIM(文字列)
LEADING,TRAILING,BOTHを省略した場合は、文字列の前後の削除文字が取り除かれます。
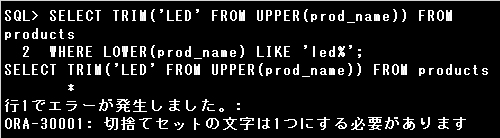
削除文字には任意の1文字を指定できますが、文字列は指定できません。
設問のSQL文ではTRIM(‘LED’ FROM UPPER(prod_name))で、大文字に変換したPROD_NAME列のデータの前後から’LED’という文字列を削除しようとしていますが、削除文字が1文字ではないのでエラーとなります。
・SELECT TRIM(REPLACE(‘Oracle Master’, ‘Master’)) FROM dual;
REPLACE関数で文字列”Oracle Master”から”Master”が削除され”Oracle “となります。
その後、TRIM関数で前後のスペースが取り除かれるので、実行結果は”Oracle”となります。
・SELECT TRIM(RPAD(‘Oracle Master’, 7, ‘ ‘)) FROM dual;
RPAD関数で長さが7文字の文字列が返されるので”Oracle “となります。
その後、TRIM関数で前後のスペースが取り除かれるので、実行結果は”Oracle”となります。
■INSTR関数
INSTR関数は、引数で指定された文字列のm文字目以降からn回目に出現した検索文字列の先頭の位置を返します。
検索文字列が見つからなかった場合は0(ゼロ)を返します。
設問のSQL文では、PROD_NAME列の1文字目から「 」(スペース)を検索し、2回目に一致した位置を返し、
<> 0でINSTR関数の結果が0でない、すなわち2回目のスペースが含まれている行を検索します。
▼例)
SELECT employee_id, employee_name FROM employees WHERE SUBSTR(employee_name, 1, 2) = ‘佐藤’;
SELECT employee_id, employee_name FROM employees WHERE INSTR(employee_name, ‘佐藤’) = 1;
SUBSTR関数は引数で指定された文字列の部分文字列を返す関数、INSTR関数は引数で指定した文字列中から検索文字列を検索し、
その位置を数値で返す関数です。
苗字が「佐藤」で始まる従業員を検索するには、EMPLOYEE_NAME列の最初の2文字が「佐藤」であればよいので、
SUBSTR関数で最初の2文字を取り出して比較するか、INSTR関数で1文字目から「佐藤」が出現するかを確認します。
INSTR関数は、引数で指定された文字列のm文字目以降からn回目に出現した検索文字列の先頭の位置を返します。
検索文字列が見つからなかった場合は0(ゼロ)を返します。
INSTR(文字列, 検索文字列[, m][, n])
設問のSQL文では、PROD_NAME列の1文字目から「 」(スペース)を検索し、2回目に一致した位置を返し、
<> 0でINSTR関数の結果が0でない、すなわち2回目のスペースが含まれている行を検索します。
SELECT prod_name FROM products
WHERE INSTR(prod_name, ‘ ‘, 1, 2) <> 0;
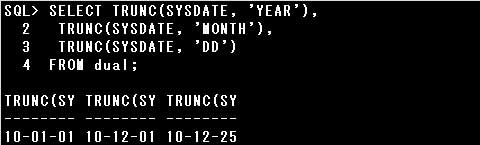
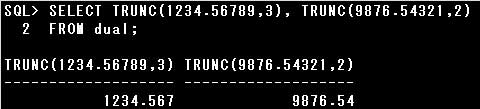
■TRUNC関数
TRUNC(SYSDATE, ‘YEAR’)の結果は”10-01-01″である
TRUNC(SYSDATE, ‘MONTH’)の結果は”10-12-01″である
TRUNC(SYSDATE, ‘DD’)の結果は”10-12-25″である
TRUNC関数は、引数で指定された日付値を切り捨てて返す関数です。
TRUNC関数は、引数で指定された日付値を切り捨てて返す関数です。
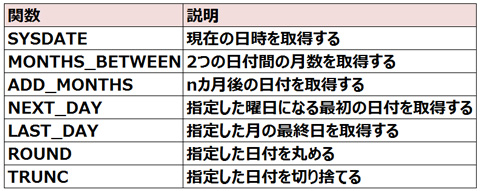
どの単位で切り捨てるのかは書式で指定します。指定できる主な書式は次のとおりです。

参考:
日付値を引数に指定するTRUNC関数は、単一行関数のうちの日付関数に分類されます。
引数で指定された日付値を切り捨てて返します。
使用法は以下の通りです。
TRUNC(日付[, 書式])
どの単位で切り捨てるのかは書式で指定します。指定できる主な書式は次のとおりです。

書式が省略された場合は”DD”が指定されたものとして処理されます。
TRUNC関数は数値関数にもありますが動作が異なりますので、注意しましょう。
その他、主な日付関数は次のとおりです。
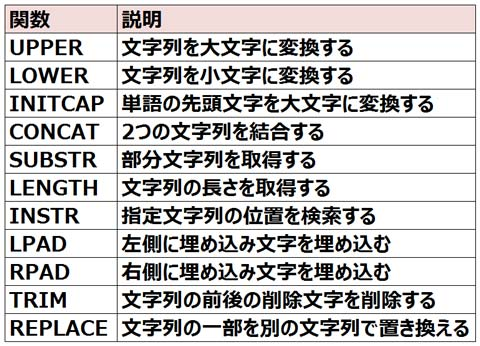
■文字列関数
文字列を連結する場合、連結演算子||で連結する方法のほか、CONCAT関数で連結することもできます。
例)
・SELECT CONCAT(‘My name is ‘, employee_name) FROM employees;
・SELECT ‘My name is ‘ || employee_name FROM employees;
参考:
CONCAT関数は、単一行関数のうちの文字関数に分類されます。
引数で指定された2つの文字列を連結して返します。
使用法は以下の通りです。
CONCAT(文字列1, 文字列2)
CONCAT関数は連結演算子||で文字列を連結した場合と同じ結果を返します。
その他、主な文字関数には次のものがあります。
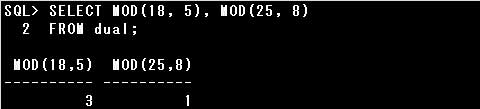


・MOD関数は引数で与えられた数値の除算の余りを返します。
使用法は以下の通りです。
MOD(n, m)
n:割られる数
m:割る数
例) MOD関数の使用例
商(割り算の結果)では無く、余りを返すので注意しましょう。商は算術演算子の「/」で求めます。
▼末尾から指定文字目を抽出
・SELECT prod_name
FROM products
WHERE INSTR(prod_name, ‘i’) != 0
AND SUBSTR(prod_name, -3, 1) = ‘ラ’;
INSTR(prod_name, ‘i’)は、PROD_NAME列から「i」を検索しその位置を返すか、見つからない場合は0(ゼロ)を返します。
!= 0は、0(ゼロ)でないということなので、INSTR関数の結果が0でない、すなわちPROD_NAME列に「i」という文字が見つかった場合という条件です。
SUBSTR(prod_name, -3, 1)は、PROD_NAME列の末尾から3文字目を示すので設問のSQL文と同じ条件です。
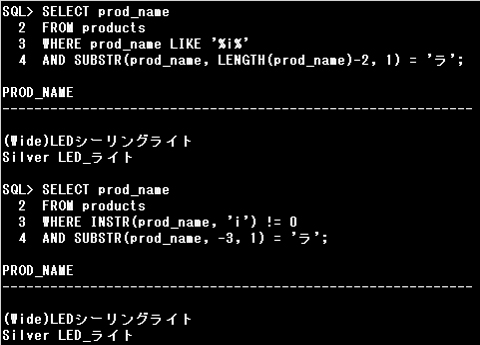
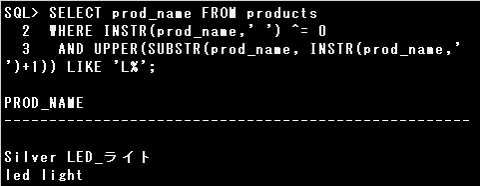
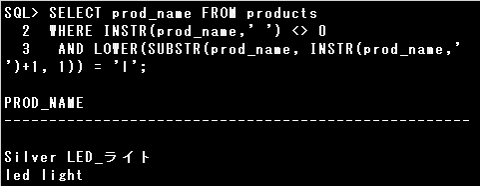
INSTR関数でPROD_NAMEのスペースの位置を検索し、結果が0でない(スペースの位置を返す)行というように記述できます。
INSTR(prod_name,’ ‘) <> 0 ※不等号は「!=」「^=」も使えます。
・スペースの後の1つ目の単語が大文字の「L」もしくは小文字の「l」で始まる
SUBSTR関数でPROD_NAMEのスペースの後の文字を抽出します。
SUBSTR(prod_name, INSTR(prod_name,’ ‘)+1) : スペースの後から末尾までの文字列を返す
SUBSTR(prod_name, INSTR(prod_name,’ ‘)+1, 1) : スペースの後の1文字を返す
また、文字列が大文字か小文字を問わない場合は、UPPER関数かLOWER関数で大文字、小文字のいずれかに変換した上で条件と比較します。
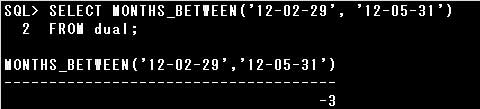
■MONTHS_BETWEEN関数
MONTHS_BETWEEN関数は、引数で指定された2つの日付間の月数を返す関数です。
MONTHS_BETWEEN(日付1, 日付2)
日付1が日付2よりも過去の日付の場合は、負の値を返します。
1ヶ月未満の値は小数で返されますが、日付1と日付2が、月の同じ日または月の最終日の場合、結果は常に整数になります。
設問では’12-02-29’のほうが過去の日付ですので、負の値が返されます。
また、’12-02-29’は2月の最終日(2012年はうるう年です)、’12-05-31’は5月の最終日ですので、整数が返されます。
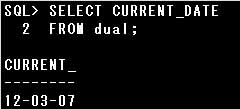
■SYSDATE関数
SYSDATE関数は接続しているデータベースサーバーの現在の日時を返す関数です。
設問ではシンガポールのデータベースサーバーに接続しているので、SYSDATE関数の実行結果はシンガポールの現在の日時となります。
参考:
SYSDATE関数は、単一行関数のうちの日付関数に分類されます。
接続しているデータベースサーバーの現在の日時を返します。
使用法は以下の通りです。
SYSDATE

SYSDATE関数には引数はありません。
なお、接続先の現在時刻ではなく、ローカルマシンの現在時刻を表示したい場合には、CURRENT_DATE関数を使用します。
CURRENT_DATE
▼主な日付関数は次のとおりです。
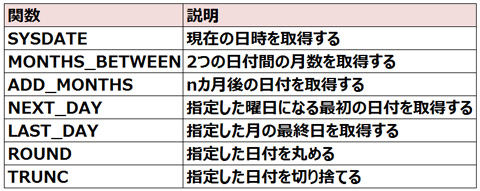
■単一行関数
Oracle Databaseに予め用意されているSQL関数には、単一行関数とグループ関数の2種類があります。
▼MOD関数
・MOD:除算の余りを返す
MOD関数は引数で指定された数値の除算の余りを返します。
MOD(n, m)
n:割られる数
m:割る数
▼TRIM関数
・TRIM:数値、日付値を切り捨てて返す
TRIM関数は引数で指定された文字列の前後にある削除文字を取り除いて文字列を返します。
TRIM([LEADING | TRAILING | BOTH] [削除文字] FROM 文字列)
または
TRIM(文字列)
▼LAST_DAY関数
・LAST_DAY:月の最終日の日付を返す
LAST_DAY関数は引数で指定された日付を含む月の最終日を返します。
LAST_DAY(日付)
▼INITCAP関数
・INITCAP:
INITCAP関数は引数で指定された文字列中の単語の先頭文字を大文字、それ以外を小文字で返します。
INITCAP(文字列)
▼SUBSTR関数
・SUBSTR:
SUBSTR関数は引数で指定された文字列のm文字目からn文字分の部分文字列を返します。
SUBSTR(文字列, m[, n])
▼ROUND関数
・ROUND:数値、日付値を四捨五入して返す
ROUND関数は引数で指定された数値または日付値を四捨五入して返します。
ROUND(数値 [, n])
ROUND(日付値[, ‘書式’])
単一行関数は、その処理内容等によって次のように分類されます。

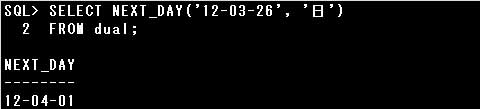
・SELECT NEXT_DAY(’12-03-26′, ‘日’) FROM dual;
12-03-26が月曜日の設定となっていますので、NEXT_DAY関数で翌日以降で最初の日曜日が返されます。
したがって実行結果は”12-04-01″となります。
・SELECT ADD_MONTHS(’12-01-01′, 4) FROM dual;
12-01-01の4ヶ月後ですので、実行結果は”12-05-01″となります。
当月日付は1カウントしないので、注意。翌月からカウントが始まる。
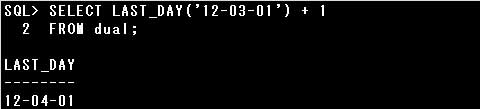
・SELECT LAST_DAY(’12-03-01′) + 1 FROM dual;
LAST_DAY関数で当月の最終日を求めると”12-03-31″となります。
その後で1日を加算しているので、翌日の”12-04-01″が返されます。
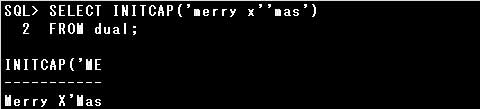
■INITCAP関数
INITCAP関数は、引数で指定された文字列中の単語の先頭文字を大文字、それ以外を小文字で返す関数です。
文字列「merry x’mas」はスペースと「’」が単語の区切りとして認識されるので、「Merry X’Mas」が返されます。
参考:
INITCAP関数は、単一行関数のうちの文字関数に分類されます。
引数で指定された文字列中の単語の先頭文字を大文字、それ以外を小文字で返します。
使用法は以下の通りです。
INITCAP(文字列)
文字列中の単語の区切りはスペースの他 ,(カンマ)や -(ハイフン)などの記号も単語の区切りとして認識されます。
■データ型
設問のSQL文のSYSDATE – hiredate(日付値 – 日付値)は、2つの日付値間の日数を計算するので、演算結果のデータ型は数値です。
選択肢のSQL文の中では、TO_CHAR(hiredate, ‘RR’)で年だけ文字列として取り出し、
それに数値を加算した場合、暗黙的なデータ変換が行われ数値データが返ります。
・SELECT SYSDATE + hiredate FROM employees;
日付値 + 日付値の演算はできません。エラーとなる
・SELECT TRUNC(hiredate) FROM employees;
日付値を引数に指定するTRUNC関数は、書式が省略された場合は”DD”が指定されたものとして
日付データ当日の午前0時を返します。結果のデータ型は日付値です。
TRUNC(日付[, 書式]) : 引数で指定された日付値を切り捨てて返す
・SELECT ADD_MONTHS(hiredate, 3) FROM employees;
ADD_MONTHS関数は、引数で指定された日付のnヶ月後の日付を返す関数です。
HIREDATEの日付から3か月後の日付を返すのでデータ型は日付値です。
・SELECT TO_NUMBER(hiredate) + 7 FROM employees;
TO_NUMBER関数は文字列を数値に変換します。引数に日付値は指定できずエラーとなる
■数値書式
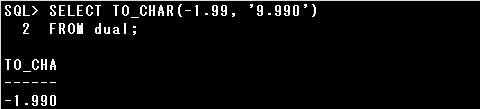
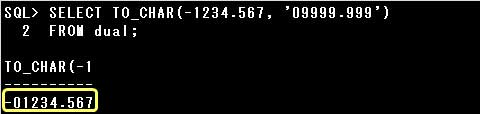
SELECT TO_CHAR(-1.99, ‘9.990’) FROM dual;
TO_CHAR関数の第2引数に指定された数値書式により、小数部分は3桁で表示し、桁数が足りない場合は0で埋めます。
整数部分は1桁で、桁数が足りない場合は0で埋めません。
第1引数に指定された数値の小数部分は2桁ですので小数点以下3桁目を0で埋めて「990」、
整数部分は1桁ですので「1」となります。
また、第1引数に指定された数値は負の値ですので、数値書式に従って変換された文字列に-符号が適用されます。
参考:
TO_CHAR関数は、数値や日付値を指定された書式に従って文字列に変換する関数です。
第1引数に数値が指定された場合は、数値を文字列へ変換します。
書式は以下の通りです。
TO_CHAR(数値 [, ‘数値書式’] [, NLSパラメータ])
数値書式は数値を文字列に変換する際のフォーマットです。数値書式に使用できる主な要素は次のとおりです。
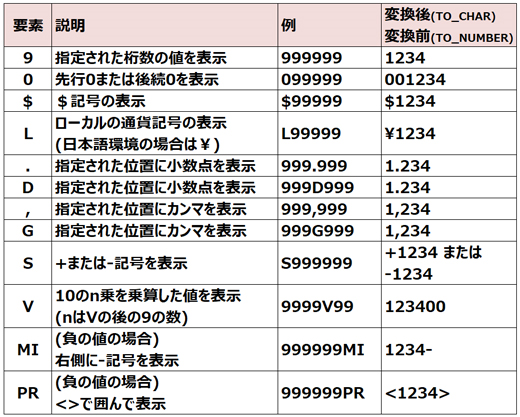
数値書式が省略された場合は、第1引数で指定された数値の有効桁数を保持するために十分な長さの文字列に変換されます。
NLSパラメータを指定すると、小数点文字、桁区切り文字、国際通貨記号、各国通貨記号を指定することができますが、
省略された場合は、現在のセッションのデフォルトのパラメータ値が使用されます。
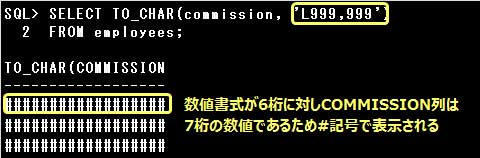
なお、第1引数で指定した数値よりも数値書式の桁数が少ない場合など、数値を適切に変換できない場合は、
次のように#記号が表示されます。
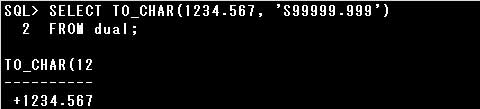
第1引数の数値にマイナスの値が指定された場合は、数値書式に従って変換された文字列に-符号が適用されます。
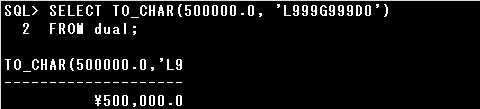
TO_CHAR関数は数値を書式化した文字列に変換します。
設問では、数値を3桁ごとにカンマ(,)で区切り、小数点以下1桁を表示しています。
カンマ(,)や小数点(.)は数値書式の中でそのまま用いることができますが、
カンマは「G」、小数点は「D」で指定することもできます。
また、¥記号を表示する場合は、ローカル通貨記号の「L」を指定します。

参考:
TO_CHAR関数は、数値や日付値を指定された書式に従って文字列に変換する関数です。
第1引数に数値が指定された場合は、数値を文字列へ変換します。
書式は以下の通りです。
TO_CHAR(数値 [, ‘数値書式’] [, NLSパラメータ])
■DECODE関数
▼エラー例)
・SELECT employee_id, employee_name, DECODE(salary, salary > 400000, ‘High’, salary < 200000, ‘low’, ‘middle’) sal FROM employees;
DECODE関数の条件に比較演算子を使用することはできません。
CASE式では、WHEN句で比較条件やINやLIKEなどの演算子が使用できますが、DECODE関数では使用できません。
▼エラー例)
・SELECT employee_id, employee_name, DECODE(NULLIF(salary, 500000), salary, 250000*1.1, NULL, hiredate) sal FROM employees;
・SELECT employee_id, employee_name, DECODE(NULLIF(salary, 500000), NULL, salary, ‘-‘) sal FROM employees;
DECODE関数の戻り値のデータ型は第3引数に指定した戻り値の型が採用されます。
異なる型を指定した場合、暗黙的なデータ変換が行われればエラーとなりませんが、暗黙的なデータ変換ができない場合はエラーとなります。
1つめのSQL文では、第3引数には数値データ(250000*1.1)が指定されており、
その後、2つ目の戻り値として日付データ(hiredate)が指定されています。
日付データは暗黙的データ変換で数値データへ変換できないため、エラーとなります。
また、2つ目のSQL文では、第3引数には数値データ(salary)が指定されており、
その後、2つ目の戻り値として文字データ(‘-‘)が指定されています。
‘-‘は暗黙的データ変換で数値データへ変換できないため、このSQL文もエラーとなります。
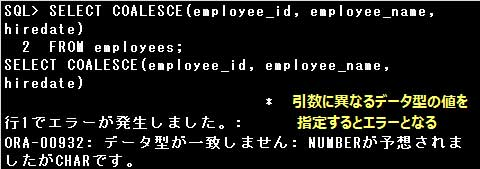
■COALESCE関数
COALESCE関数は引数の値を判定し、最初に見つかったNULL値以外の値を返す関数です
なお、COALESCE関数の引数は、すべて同じデータ型の値でなければなりません。
異なるデータ型の値を指定するとエラーとなります(暗黙的なデータ変換は行われません)。
すべての引数がNULL値の場合、COALESCE関数はNULL値を返します。
選択肢のSQL文のうち、
・SELECT COALESCE(employee_id, employee_name, hiredate) FROM employees;
は、EMPLOYEE_ID列、EMPLOYEE_NAME列、HIREDATE列のデータ型がそれぞれNUMBER型、VARCHAR2型、
DATE型であるためエラーとなります。
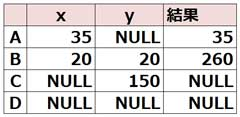
▼次のSQL文の結果として誤っているものはどれですか。
SELECT x, y, COALESCE(x * 12 + y, x, y)
FROM dual;

■日付値・日付書式
▼設問
現在の日付は2012年06月23日です。
1999年4月1日から現在までの日数を求めるには、どのSQL文を実行しますか(該当するものをすべて選択してください)。
ただし、実行環境は英語環境とし、デフォルトの日付の表示形式は「RR-MM-DD」とします。
日付値から日付値を減算すると、2つの日付間の日数を求めることができます。
設問では「1999年4月1日」から現在までに経過した日数を求めるので、2つの日付の日付値を取得し、減算を行います。
現在の日付の日付値はSYSDATE関数で取得することができ、「1999年4月1日」の日付値はTO_DATE関数を使用して日付値を取得します。
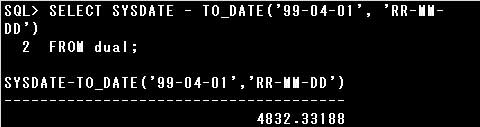
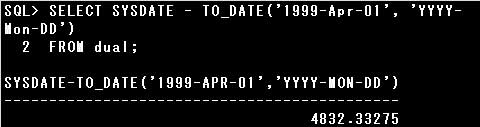
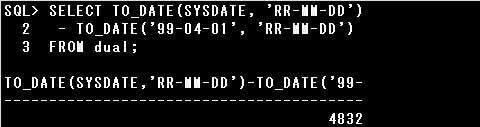
▼正しいSQL例)
SELECT SYSDATE – TO_DATE(’99-04-01′, ‘RR-MM-DD’) FROM dual;
SELECT SYSDATE – TO_DATE(‘1999-Apr-01’, ‘YYYY-Mon-DD’) FROM dual;
SELECT TO_DATE(SYSDATE, ‘RR-MM-DD’) – TO_DATE(’99-04-01′, ‘RR-MM-DD’) FROM dual;
▼エラー例)
・SELECT TO_CHAR(SYSDATE) – ’99-04-01′ FROM dual;
文字列同士の演算はできませんので、エラーとなります。
・SELECT SYSDATE – TO_DATE(’99-04-01′, ‘YY-MM-DD’) FROM dual;
日付書式の「YY」を指定すると、現在の世紀の下2桁の年のを返すので、TO_DATE関数の結果「2099年4月1日」に変換されます。
・SELECT SYSDATE – TO_DATE(’01-Apr-99′) FROM dual;
TO_DATE関数の日付書式が省略された場合は、デフォルトの日付書式が使用されます。
設問では、デフォルトの日付書式は「RR-MM-DD」ですので、文字列と日付書式が一致せず、エラーとなります。
▼正しいSQL)
・SELECT startdate + ’10’ FROM prod;
DATE型のSTARTDATE列の値に文字リテラルを加算しようとしています。
DATE型と文字型の加算はできませんが、’10’は暗黙的データ変換で数値の10に変換されるため、
STARTDATE列の値に10日を加算した値が返されます。
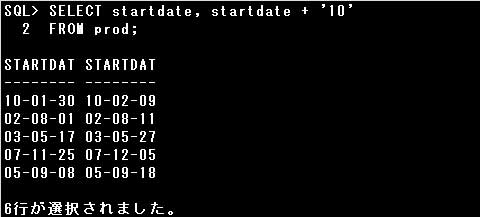
・SELECT * FROM prod WHERE startdate = ’10-01-30′;
WHERE句に指定された文字リテラルが暗黙的データ変換でDATE型の値に変換され、条件に該当する列が取り出されます。
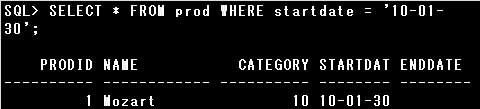
・SELECT * FROM prod WHERE startdate > ’05/01/01′;
WHERE句に指定された文字リテラルが暗黙的データ変換でDATE型の値に変換され、条件に該当する列が取り出されます。
ここで、日付書式が”RR-MM-DD”であるのに、文字リテラルを”RR/MM/DD”の形式として、異なる区切り文字で指定しています。
しかしOracle Databaseは区切り文字に関して一定の柔軟性を持って変換しますので、エラーとはなりません。
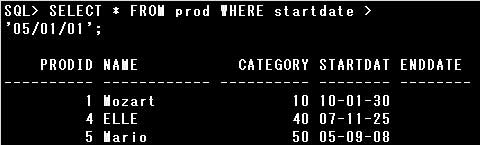
▼エラー例)
・SELECT startdate + ’12-01-01′ FROM prod;
DATE型のSTARTDATE列の値に日付リテラルを加算しようとしていますが、DATE型同士の加算はできないため、
Oracle Databaseは日付リテラルを数値へと暗黙的データ変換しようとします。
ですが、’12-01-01’を数値へ変換できないためエラーとなります。

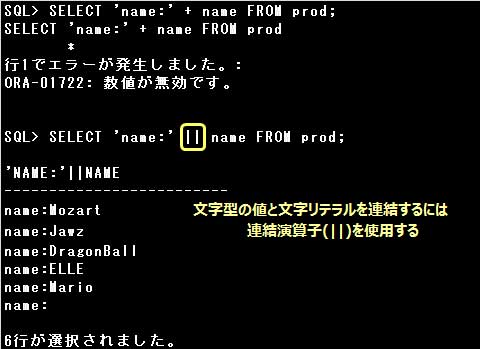
・SELECT ‘name:’ + name FROM prod;
文字リテラルと文字型の値を連結する場合は、連結演算子(||)を使用します。”+”では連結できませんのでエラーとなります。
▼日付書式
日付書式はデフォルトで埋め込みモードが有効となっています。
埋め込みモードが有効の場合、数値が1桁の場合に先頭に0付きで表示されたり、文字の前後にスペース付きで表示されます。
埋め込みモードを無効にするには、日付書式に「FM」を指定します。
設問では、「01st」ではなく「1st」で埋め込みモード無効にしている。
「June」の後ろにスペースがないことから、埋め込みモードを無効にして問合せを実行したことがわかります。
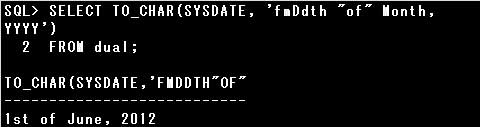
「FM」が指定される度に埋め込みモードの有効/無効が切り替わる
▼エラー例)
・SELECT SYSDATE – TO_DATE(’99-04-01′, ‘YY-MM-DD’) FROM dual;
日付書式の「YY」を指定すると、現在の世紀の下2桁の年のを返すので、TO_DATE関数の結果「2099年4月1日」に変換されます。
▼エラー例)
・SELECT SYSDATE – TO_DATE(’01-Apr-99′) FROM dual;
TO_DATE関数の日付書式が省略された場合は、デフォルトの日付書式が使用されます。
設問では、デフォルトの日付書式は「RR-MM-DD」ですので、文字列と日付書式が一致せず、エラーとなります。
▼日付書式2
TO_DATE関数は、文字列を指定された書式に従って日付値に変換する関数です。
TO_DATE(文字列 [, ‘日付書式’] [, NLSパラメータ])
設問のSQL文のように文字列と日付書式のフォーマットが一致しない場合、Oracle Databaseは別の書式要素の適用を試行します。
設問では、’RR-MM-DD’書式に対して、’2099/12/31’と異なるフォーマットの文字列が指定されていますが、
Oracle Databaseは’RR’要素を’RRRR’要素に置き換えて試行するため、「2099/12/31」として扱われます。
‘RRRR’要素は明示的に4桁の数値が指定された場合、’YYYY’要素と同様にそのまま4桁の年号として扱われます。
また、「-」,「/」,「.」,「:」などの英数字以外の半角記号は、設問のように異なる記号を指定しても、
内部的に区切り記号として一致させることができるのでエラーとなりません。
TO_DATE関数だけでは指定した日付書式”RR-MM-DD”で出力されますので、最後にTO_CHAR関数で”YYYY-MM-DD”という
書式の文字列に変換して、4桁の西暦を表示しています。

TO_DATE関数の日付書式やNLSパラメータは省略可能です、省略された場合はセッションのデフォルト値が適用されます。
日本語環境で日付書式のデフォルト値は「RR-MM-DD」ですので、設問のSQL文は正常に実行され、「2012-05-21」が表示されます。


日付を表す文字列を書式化して表示するには、文字列をTO_DATE関数で日付値に変換し、
その後、TO_CHAR関数で日付書式にしたがって文字列に変換します。
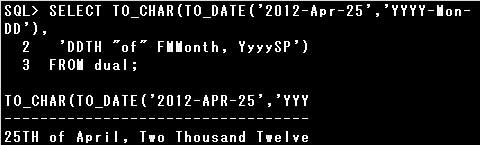
設問の表示形式では、
・「年」はスペル表記
・「月」は名前表記
・「日」は順序表記
ですので、「年」には「SP」要素を指定、「月」は「MM」ではなく「Month」を指定、
「日」は「TH」要素を指定しなければなりません。
また、埋め込みモードが有効になっていると、「Month」を指定した時に末尾にスペースが表示されるので、
「FM」要素を指定して埋め込みモードを無効にする必要があります。
▼正しいSQL)
SELECT TO_CHAR(TO_DATE(‘2012-Apr-25′,’YYYY-Mon-DD’), ‘DDTH “of” FMMonth, YyyySP’) FROM dual;

■暗黙的なデータ変換
Oracle Databaseでは、データ型の変換が意味を持つ場合に、
自動的にデータ型の変換が行われます(暗黙的なデータ変換といいます)。
そのため、関数の引数やWHERE句の条件等に期待されるデータ型以外の値を指定したとしても、エラーとならない場合があります。
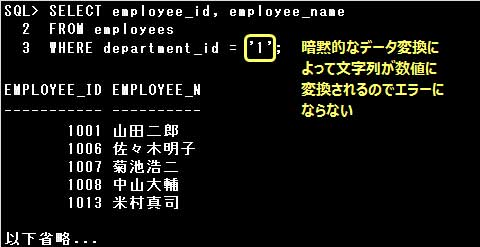
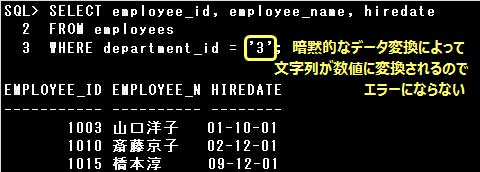
・SELECT employee_id, employee_name FROM employees WHERE department_id = ‘1’;
DEPARTMENT_ID列は数値なので、department_id = 1と指定するべきですが、’1’の部分が暗黙的なデータ変換により
数値に変換されるので、エラーにはなりません。
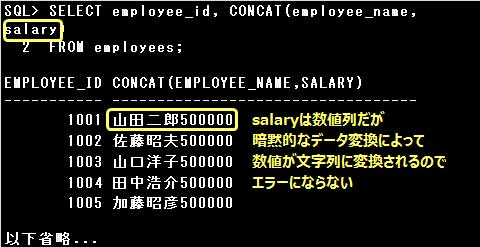
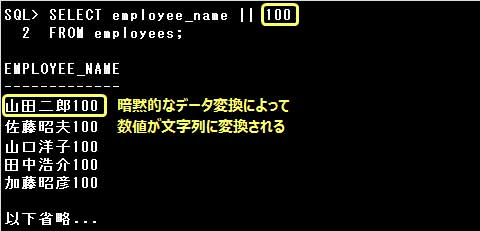
・SELECT employee_id, CONCAT(employee_name, salary) FROM employees;
CONCAT関数の引数には文字列データを指定するべきですが、salary(数値)が暗黙的なデータ変換により
文字列に変換されるので、エラーにはなりません。
・SELECT employee_id, employee_name, SUBSTR(hiredate, 1, 5) FROM employees;
SUBSTR関数の引数には文字列データを指定するべきですが、hiredate(日付値)が暗黙的なデータ変換により
文字列に変換されるので、エラーにはなりません。
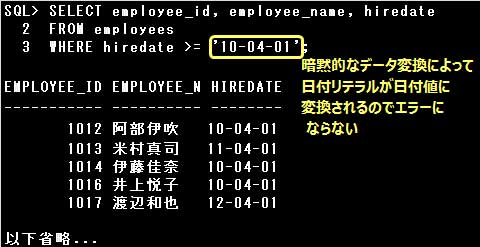
・SELECT employee_id, employee_name, hiredate FROM employees WHERE hiredate >= ’10-04-01′;
HIREDATE列は日付値なので、TO_DATE関数で日付値に変換してから指定するべきですが、
’10-04-01’の部分が暗黙的なデータ変換により日付値に変換されるので、エラーにはなりません。

参考:
Oracleでは、値をあるデータ型から別のデータ型へ変換する事をサポートしています。
データ型の変換には、「暗黙的なデータ変換」と「明示的なデータ変換」があります。
[暗黙的なデータ変換]
暗黙的なデータ変換とは、データ型の変換が意味を持つ場合に、Oracle Databaseが自動的に行う変換です。以下のような場合に変換が行われます。
・数値を指定すべきところに文字列が指定された場合:文字列を数値に変換
・日付リテラルが指定された場合:デフォルトの日付の表示書式にしたがって日付値に変換
・文字列を指定すべきところに数値が指定された場合:数値を文字列に変換
・文字列を指定すべきところに日付値が指定された場合:日付値を文字列に変換
例) 文字列を数値に変換
例2) 数値を文字列に変換
例3) 日付リテラルを日付値に変換

ただし、暗黙的なデータ変換はSQL文が分かりにくくなったり、パフォーマンスに悪影響を及ぼす場合があります。
また、実行環境によっては正常に動作しない可能性があるなど、汎用性にも欠けます。
よって次に説明する明示的なデータ変換を使用することが推奨されています。
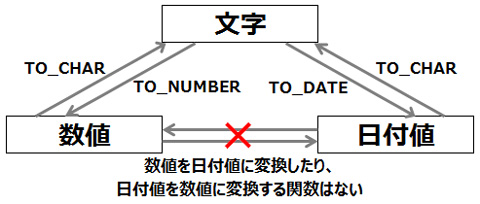
[明示的なデータ変換]
明示的なデータ変換とは、変換関数を使用して行うデータ変換のことです。Oracle Databaseにはさまざまな変換関数が用意されてます。
ただし、数値を日付値に変換したり、日付値を数値に変換する関数はありませんので気を付けて下さい。
以下は主な変換関数です。

▼エラー例)
・SELECT NVL(MONTHS_BETWEEN(SYSDATE, hiredate), SYSDATE) FROM employees;
まずMONTHS_BETWEEN関数が実行され、2つの日付間の月数を表す数値が返されます。
そして、NVL関数が実行されますが、NVL関数の第1引数が数値であるのに対し、
第2引数は日付値で、データ型が異なるため、このSQL文はエラーとなります。

■CASE式
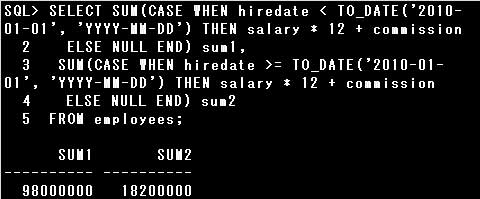
CASE式には単純CASE式と検索CASE式の2種類がありますが、設問のSQL文で使用されているCASE式は検索CASE式です。
CASE式は関数の引数として記述することもできますし、デフォルトの戻り値にNULL値を指定することもできます。
■NULLIF関数
NULLIF関数は第1引数と第2引数が等しい場合はNULL値を、等しくない場合は第1引数の値を返します。
なお、第1引数にはリテラルのNULL値以外の値を指定しなければなりませんが、第2引数はNULL値を指定できます。
・2つの値を比較して、等しい場合にNULLを返す
・1番目の引数にリテラルNULL値を指定できない
・2番目の引数にリテラルNULL値を指定できる
■型変換
TO_NUMBER関数は文字列を数値へ変換します。
TO_NUMBER(文字列 [, ‘数値書式’] [, NLSパラメータ])
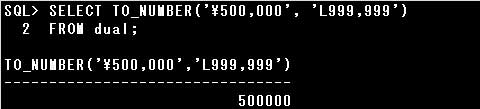
▼正しいSQL例)
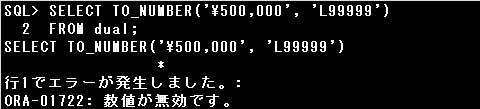
・TO_NUMBER(‘¥500,000’, ‘L999,999’)
変換する文字列には日本語環境でデフォルトの通貨記号である「¥」が含まれているため、
数値書式にはローカル通貨記号の”L”を指定します。
また、3桁目と4桁目の間にカンマ(,)がありますので、数値書式にもカンマ(,)を指定しなければなりません。
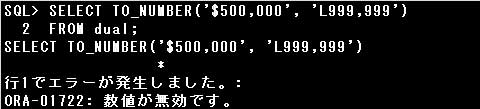
▼エラー例)
・TO_NUMBER(‘$500,000’, ‘L999,999’)
文字列の通貨記号と数値書式の通貨記号が異なるため、エラーとなります。
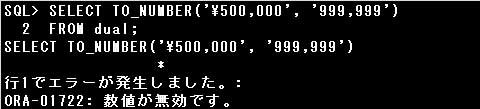
・TO_NUMBER(‘¥500,000’, ‘999,999’)
文字列には通貨記号が含まれていますが、数値書式に通貨記号が指定されていないため、エラーとなります。
・TO_NUMBER(‘¥500,000’, ‘L99999’)
文字列と数値書式の桁数が異なるため、エラーとなります。
■NVL関数・NVL2関数
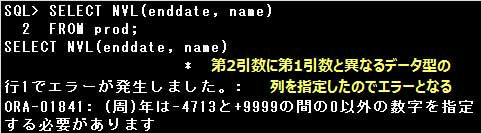
NVL関数は、第1引数の値がNULL値の場合は第2引数の値を返し、第1引数の値がNULL値以外の場合はそのまま第1引数の値を返します。
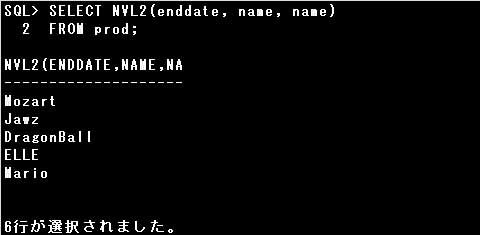
NVL2関数は、第1引数の値がNULL値以外の場合は第2引数の値を返し、第1引数の値がNULL値の場合は第3引数の値を返します。
また、NVL関数の第2引数に指定する式は、第1引数の式と同じデータ型でなければなりません。
NVL2関数の第3引数に指定する式は、第2引数の式と同じデータ型でなければなりませんが、第1引数とは異なるデータ型でも構いません。
■SELECT文で指定する句の順番
SELECT文に指定する句の順序は、
1.SELECT句
2.FROM句
3.WHERE句
4.GROUP BY句
5.HAVING句
6.ORDER BY句
※GROUP BY句とHAVING句は入れ替えができます。
■グループ関数
グループ関数は、複数行のデータをグループ化して、集計処理を行った結果をグループ毎に1つだけ返す関数で、
SELECT句、HAVING句、ORDER BY句で指定することができます。
集計するデータにNULL値が含まれている場合は、COUNT(*)を除き集計時に無視されます。
またグループ関数では2レベルまでネストが可能です。
DISTINCTオプションを指定すると、重複したデータは1度だけ処理されます。
・行のグループごとに1つの結果を返す
・グループ関数にDISTINCTをオプションとして指定することができる
グループ関数はSELECT句、HAVING句、ORDER BY句で使用できますが、WHERE句では使用できません。
また、主なグループ関数であるCOUNT,MAX,MIN,SUM,AVG関数の引数には、次の値を指定します。
・COUNT関数 : 数値型、文字列型、日付型の値を返す式または列と*(アスタリスク)
・MAX/MIN関数 : 数値型、文字列型、日付型の値を返す式または列
・SUM/AVG関数 : 数値型の値を返す式または列
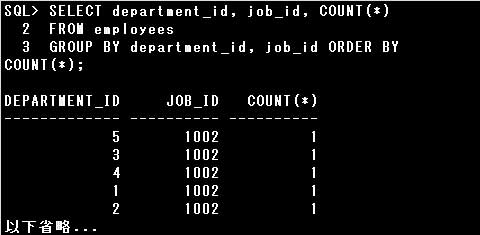
SELECT文にGROUP BY句を指定すると、関連のある行をグループ化できますが、GROUP BY句を指定する場合にはいくつかの要件を満たす必要があります。
・GROUP BY句には1つ以上の列を指定する
・GROUP BY句に列別名を指定することはできない
・GROUP BY句を指定したSELECT文のSELECT句には、GROUP BY句で指定した列、もしくはグループ関数のみ指定できる
(select句に指定したグループ関数以外の列はすべてgroup by句で指定する必要がある)
・GROUP BY句とORDER BY句を併用する場合、ORDER BY句にはGROUP BY句で指定した列、もしくはグループ関数のみ指定できます
(グループ化されている列の値を、グループ化されていない列の値を基準に並べ替える事はできない為)
また、GROUP BY句はWHERE句とORDER BY句の間に指定します。
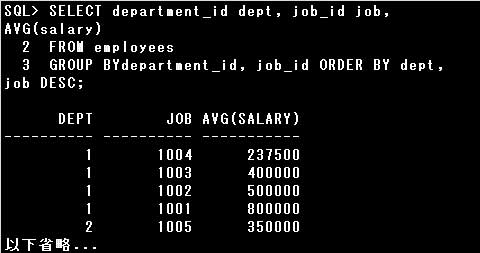
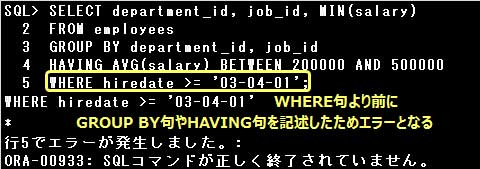
▼エラーSQL例)
・SELECT department_id dept, job_id job, MIN(salary) FROM employees GROUP BY dept, job ORDER BY 1, 2 DESC;
GROUP BY句に列別名を指定できません。
▼エラーSQL例)
・SELECT department_id dept, job_id job, MAX(salary) FROM employees GROUP BY department_id, job_id ORDER BY salary;
SELECT文でGROUP BY句とORDER BY句を併用する場合、ORDER BY句にはGROUP BY句で指定した列かグループ関数のみ指定できます。
したがって、SALARY列をORDER BY句に指定できません。
▼正しいSQL例)
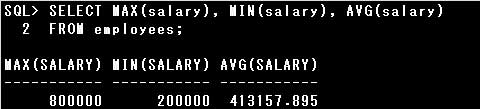
・SELECT MAX(salary), MIN(salary), AVG(salary) FROM employees;
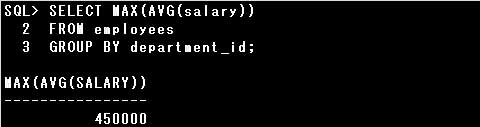
・SELECT MAX(AVG(salary)) FROM employees GROUP BY department_id;
SELECT文にGROUP BY句を指定しない場合、グループ関数を使用することはできますが、グループ関数をネストすることはできません。
また、GROUP BY句を指定しても、グループ関数は2レベルまでしかネストすることができません。
▼エラーSQL例)
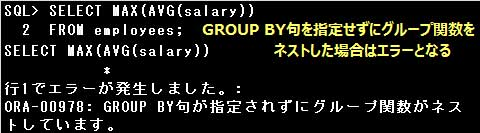
・SELECT AVG(MIN(salary)) FROM employees;
グループ関数をネストする場合は、必ずGROUP BY句を指定しなければなりません。

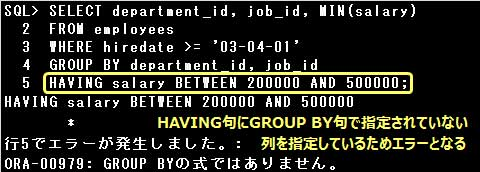
▼エラーSQL例)
・SELECT AVG(MIN(MAX(salary))) FROM employees GROUP BY department_id, job_id;
グループ関数はGROUP BY句を指定しても、2レベルまでしかネストできないためエラーとなります。

▼エラーSQL例)
・SELECT MAX(AVG(hiredate)) FROM employees GROUP BY department_id;
AVG関数に引数には数値型を指定しなければなりません。
主なグループ関数であるCOUNT,MAX,MIN,SUM,AVG関数の引数には、次の値を指定します。
・COUNT関数 : 数値型、文字列型、日付型の値を返す式または列と*(アスタリスク)
・MAX/MIN関数 : 数値型、文字列型、日付型の値を返す式または列
・SUM/AVG関数 : 数値型の値を返す式または列
参考:
グループ関数は、GROUP BY句を指定した場合に限りネストすることができます。
グループ関数のネストレベルは2レベルまでです。
グループ関数はSELECT句、HAVING句、ORDER BY句で使用することができます。
▼HAVING句のグループ関数はネスト不可。
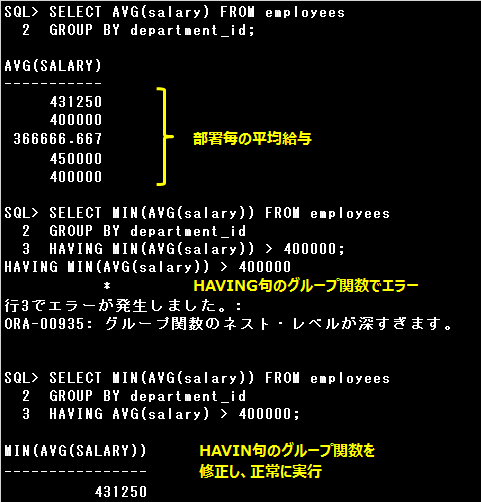
▼設問
次の問合せを実行したところエラーとなりました。
正常に実行するためにはどこを修正すればよいでしょうか。
SELECT MIN(AVG(salary)) FROM employees
GROUP BY department_id
HAVING MIN(AVG(salary)) > 400000;
設問のSQL文では、HAVING句で取り出すグループを制限していますが、HAVING句ではグループ関数をネストできません。
SELECT句ではグループ関数を2つまでネストできます。
部署(DEPARTMENT_ID)毎の給与(SALARY)の平均値が400000を超えるもので一番最小値を出力します。
正常に実行するために、HAVING句のグループ関数をMIN(AVG(salary))から(AVG(salary)に修正しています。
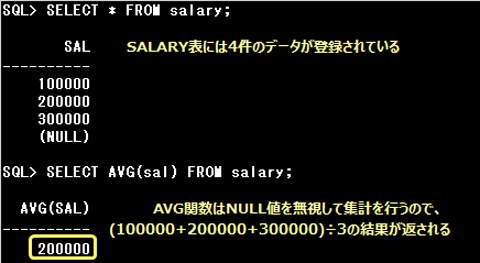
▼NULLは、AVG関数では、カウントしない
EMP2表のSALARY列に、以下の3件のデータが格納されているとします。
100000, NULL, 500000
SELECT AVG(salary) FROM emp2;
グループ関数では、COUNT関数の引数に*(アスタリスク)が指定された場合を除き、NULL値を無視して集計処理を行います。
したがって、設問のAVG関数では、
(100000 + 500000) ÷ 2
の結果が返されます。

グループ関数では、COUNT関数に引数に*(アスタリスク)が指定された場合を除き、NULL値を無視して集計処理を行います。
AVG関数で平均を求める場合に集計するデータにNULL値が含まれていると、AVG関数はNULL値を除いたデータの平均値を返します。
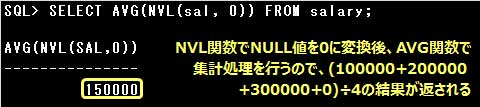
NULL値を含めた全件数で割った平均を求めたい場合は、AVG関数の集計処理前にNVL関数などでNULL値を”0″に変換することで、
全件数の平均値を求めることができます。
■SQL関数
SQL関数とはOracleに予め用意されている関数のことです。
主に以下のような関数があります。
[単一行関数]
MOD(m, n) :mをnで割った余りを返す
POWER(m, n) :mをn乗したべき乗を返す
ROUND(m [,n]) :mを小数点以下n桁に四捨五入した値を返す
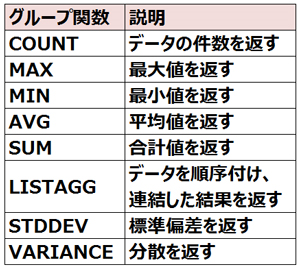
[グループ関数]
COUNT([DISTINCT | ALL] {列名 | 列名を含む式}) :データの件数を返す
MAX([DISTINCT | ALL] {列名 | 列名を含む式}) :最大値を返す
MIN([DISTINCT | ALL] {列名 | 列名を含む式}) :最小値を返す
AVG([DISTINCT | ALL] {列名 | 列名を含む式}) :平均値を返す
SUM([DISTINCT | ALL] {列名 | 列名を含む式}) :合計値を返す
▼SQL関数として、無いもの
・減算
・除算の商を求める
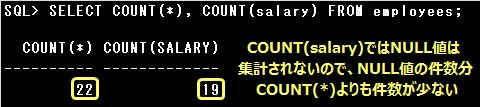
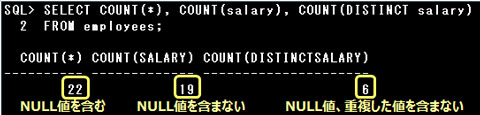
■COUNT関数
COUNT関数は取り出されたデータの件数を返す関数です。
引数には列名や数値型、文字列型、日付型の値を返す式の他、*(アスタリスク)を指定できます。
また、重複した値がある場合の処理方法をDISTINCT/ALLオプションで指定できます。

・COUNT(DISTINCT salary)は重複した値やNULL値を除いたデータの件数を返す
・COUNT(*)はNULL値も含めた全てのデータ件数を返す
・引数に日付型の列を指定できる
COUNT関数の引数に列名や式を指定した場合、NULL値はカウントされません。
参考:
COUNT関数は取り出されたデータの件数を返す関数です。
使用法は以下の通りです。
COUNT({[DISTINCT | ALL] 列名 | 式})
COUNT(*)
DISTINCT/ALLオプションは、グループ内に重複した値がある場合の処理方法を指定するオプションです。
・DISTINCT:重複した値を除いて処理する
・ALL:全ての値を処理する(デフォルト値)
COUNT関数の引数には列名や数値型、文字列型、日付型の値を返す式の他、*(アスタリスク)を指定することもできます。
引数に*(アスタリスク)が指定された場合と列名や式が指定された場合とでは、次のような違いがあります。

■結合
表の結合を行う際に、表接頭辞として「表名」または「表別名」を指定すると、メモリの使用量が節約でき、
パフォーマンスの向上につながります。ただし、同じ表の表接頭辞として「表名」と「表別名」を混在することはできません。
また、結合条件にBETWEEN句を指定して結合することができます(等号(=)以外の演算子を使用した結合を「非等価結合」といいます)。
・表接頭辞を使用するとパフォーマンスが向上する
・結合条件にBETWEEN演算子を使用することができる
・3つ以上の表も結合することができます。
・同じ表を2つの表に見立てて結合することもできます(自己結合といいます)。
・表別名を定義した表に対し、元の表名を表接頭辞として指定することはできません。
Oracle Databaseでは、複数の表を関連付けデータを取り出すことができます。複数の表を関連付けることを表の結合といいます。
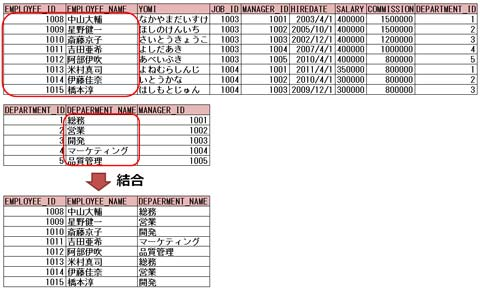
Oracle Databaseではいろいろな方法で表を結合することができます。主な結合方法は次の通りです。

表の結合時、結合するそれぞれの表に同じ名前の列がある場合は、どの表の列であるかを明確にするために、
列名に表接頭辞を指定しなければなりません。
表接頭辞には表名、または表別名を使用することができます。

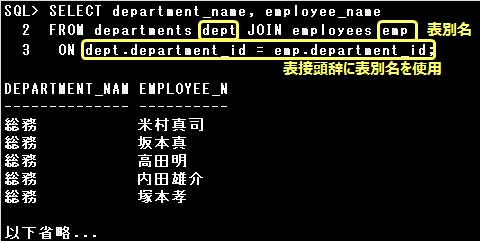
ただし、同じ表に対する表接頭辞として、表名と表別名を混在して記述することはできません。
表に表別名を定義した場合、表接頭辞には表別名を使用します。
▼Oracle独自の結合構文
Oracle独自の結合構文では、
・結合する表名は,(カンマ)で区切ってFROM句に指定
・結合条件はWHERE句に指定
・結合条件以外の条件はWHERE句に指定した結合条件の後にAND演算子で指定
します。

正しく実行するには、WHERE句に結合条件を指定します。

▼1つのSQL文で実行するために、副問合せまたは結合を使用しなければならない問合せはどれですか(2つ選択して下さい)。
・部署が3の部署の最高給与を表示する
SELECT MAX(salary) FROM employees WHERE department_id = 3;
・「山口洋子」と同じ部署の従業員を表示する
SELECT department_id, employee_name FROM employees
WHERE department_id = (SELECT department_id FROM employees WHERE employee_name = ‘山口洋子’);
・給与が40万円以上の従業員の平均給与を表示する
SELECT AVG(salary) FROM employees WHERE salary >= 400000;
・従業員とその上司の名前を表示する
SELECT e.employee_name, m.employee_name FROM employees e LEFT OUTER JOIN employees m
ON e.manager_id = m.employee_id;
・入社日が2001年10月より前で上司のいない従業員を表示する
SELECT employee_name, hiredate FROM employees
WHERE hiredate < ’01-10-01′ AND manager_id IS NULL;
■EXISTS・IN・NOT EXISTS・NOT IN演算子
EMPLOYEES表から、部下のいない従業員の名前を表示します。
各従業員のMANAGER_ID列に上司のEMPLOYEE_IDが登録されていますが、上司がいない従業員も存在します。
次の2つのSQL文の実行結果として正しいものはどれですか。
1) SELECT m.employee_name FROM employees m
WHERE NOT EXISTS (SELECT e.employee_id FROM employees e WHERE e.manager_id = m.employee_id);
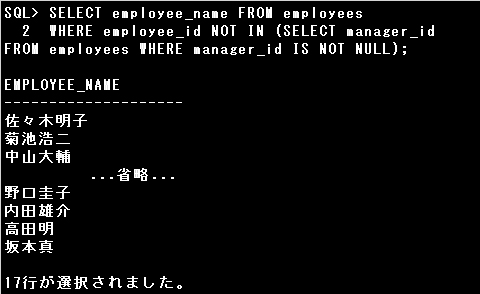
2) SELECT employee_name FROM employees
WHERE employee_id NOT IN (SELECT manager_id FROM employees);
1)のSQL文のNOT EXISTS演算子は、主問合せで取り出した1行が副問合せの条件を満たしていない場合、
つまり副問合せの結果が1行も返されない場合にTRUEとして評価され、主問合せの結果が返されます。
主問合せのm表で取り出したデータが副問合せの「e.manager_id = m.employee_id」という条件を満たしていない場合、
部下のいない従業員として主問合せは結果を返します。正しいSQL文です。
2)のSQL文のNOT IN演算子はリスト内の全ての値と等しくない場合にTRUEを返しますが、
副問合せの結果にNULL値が含まれていると全ての値と等しくないという判定がされません。
副問合せのMANAGER_ID列にNULL値が含まれているため、エラーとはなりませんが主問合せは1行もデータを返しません。
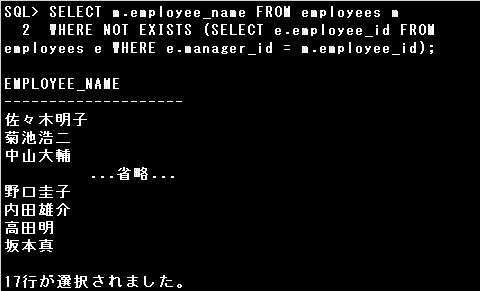

▼2)のSQL文で目的の結果を得るには、副問合せの結果にNULL値が含まれないように「IS NOT NULL」条件を追加します。
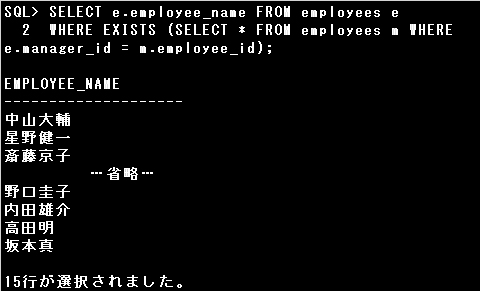
XISTS演算子は、副問合せの結果が1行以上返される場合にTRUEとして評価される演算子です。
主問合せのWHERE句に列名と比較演算子を指定する代りに、EXISTS演算子を指定します。
WHERE EXISTS (副問合せ)
EXISTS演算子で設問の結果を得るには、主問合せで取り出したEMPLOYEES表 e の各行に対して副問合せを実行し、
EMPLOYEES表 m のEMPLOYEE_ID列にMANAGER_ID列と同じ値があればTRUEを返し、上司がいる従業員として主問合せの行を表示します。
このSQL文はIN演算子を使用したSQL文にも置き換えられます。
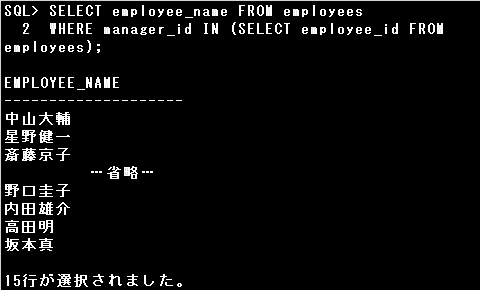
EXISTS演算子の後の副問合せが括弧()で囲まれていないため、エラーとなります。
参考:
WHERE句に指定された副問合せがNULL値を戻した場合、主問合せの結果は0件になります。
ただし、IN演算子の場合は、リスト内のいずれかの値と等しい場合にTRUEを返すため、
IN演算子の値のリストにNULL値が含まれていても、NULL値以外の値と比較対象の値が等しければ、主問合せでデータが取り出されます。
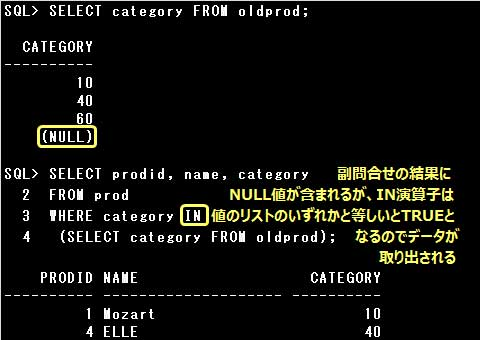
NOT IN演算子の場合は、リスト内の全ての値と等しくない場合にTRUEを返しますが、
NOT IN演算子の値のリストにNULL値が含まれていると、NULL値と比較対象の値の比較結果がNULL値になるので、
全ての値と等しくないという判定がなされません。そのため、主問合せではデータが1件も取り出されません。
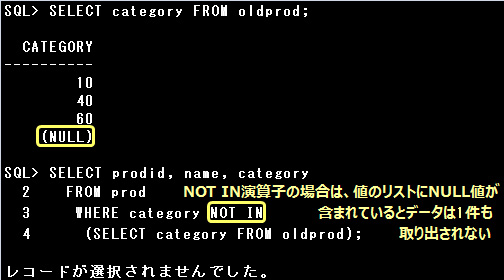
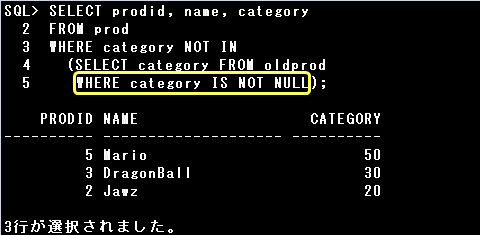
上記の例で、OLDPROD表に含まれないCATEGORY列の値をPROD表から取り出したいのであれば、
以下のようにNULLを除外して実行する必要がありますので、注意しましょう。
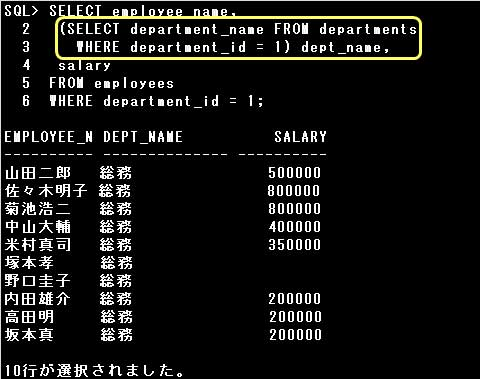
■副問合せ2
副問合せは、SELECT文のSELECT句、FROM句、WHERE句、HAVING句、ORDER BY句の他、INSERT文やUPDATE文等のDML文でも使用することができます。
・SELECT句
・FROM句
・WHERE句
・HAVING句
・ORDER BY句
・INSERT文
・UPDATE文などDML文で使用可能



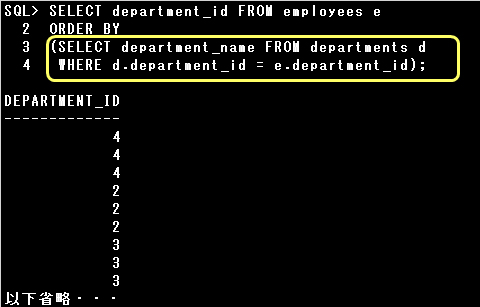
[ORDER BY句]
※副問合せの中でそのFROM句に無い表を参照する場合(副問合せの外側にある表を参照する場合)、相関副問合せと呼ばれます。
▼Oracle DatabaseではSQL文の中に別のSQL文を入れ子にして実行することができ、入れ子の内側の問合せのことを副問合せといいます
(副問合せに対し、外側の問合せを主問合せといいます)。
副問合せは、SELECT文のSELECT句、FROM句、WHERE句、HAVING句の他、INSERT文やUPDATE文等のDML文でも使用することができます。
副問合せには、次のようにいろいろな使用方法があります。
・SELECT文のSELECT句、FROM句、WHERE句、HAVING句、ORDER BY句や、INSERT文、UPDATE文等のDML文で使用できる
・主問合せと副問合せで異なる表にアクセスできる
・1つの主問合せに対し、複数の副問合せを指定できる
・副問合せをネストできる(WHERE句に指定した副問合せでは255レベルのネストが可能)
・副問合せの中でGROUP BY句やHAVIMG句、ORDER BY句を使用できる
なお、副問合せには、1件のデータを返す単一行副問合せと複数行の結果を返す複数行副問合せがあります。
主問合せと副問合せのFROM句には異なる表を指定することができます。
副問合せには複数件のデータを返す問合せ(複数行副問合せ)を指定することもできます。
▼次の問合せを実行したところエラーとなりました。エラーの原因は何ですか。
ただし、MANAGER_IDはDEPARTMENT_ID毎に異なる値が登録されているものとします。
SELECT employee_id, employee_name
FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE manager_id =
(SELECT employee_id
FROM employees
WHERE salary =
(SELECT MAX(salary)
FROM employees)));
解説
副問合せはネストすることができます。WHERE句に指定する副問合せでは最大255レベルまでのネストが可能です。
ネストした問合せでは、内側の問合せから実施されます。
設問のSQL文では、最初に一番内側の副問合せである、
SELECT MAX(salary)
FROM employees
が実施されます。この問合せでは、全従業員のなかで一番給与額の多い従業員の給与額を1件返します。
次に、
SELECT employee_id
FROM employees
WHERE salary = (内側の問合せの結果)
が実施されます。この問合せでは、一番給与額の多い従業員の従業員番号を返します。
ここで、一番給与額の多い従業員が複数人いた場合、複数件のデータを返します。
次に、
SELECT department_id
FROM departments
WHERE manager_id = (内側の問合せの結果)
が実施されます。この問合せでは、マネージャー番号が一番給与額の多い従業員と一致する部署の部署番号を返します。
もしも内側の問合せから複数件のデータが返された場合は、単一行演算子を使用しているため、エラーとなります。
また、マネージャー番号が一番給与額の多い従業員と一致しない場合は、NULL値を返します。
エラーとならなかった場合は最後に、主問合せで、マネージャー番号が一番給与額の多い従業員と
一致する部署の従業員番号と従業員名が取り出されます。先の副問合せからNULL値が返された場合は、
エラーとはならず、データが1件も表示されません。
したがって、エラーが発生する可能性があるのは、一番給与額の多い従業員が複数人いる場合となります。
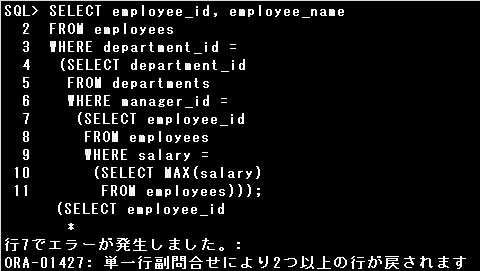
WHERE句に指定された副問合せでは最大255レベルまでネストすることができます。
グループ関数にNULL値が渡された場合、NULL値を無視して集計処理を行います。
▼単一行副問合せは主問合せに1件のデータを返す副問合せです。
副問合せがWHERE句などに指定する条件の一部として使用される場合、
単一行副問合せでは単一行演算子を使用して条件を記述します。
ただし、ANY演算子などの複数行演算子と単一行副問合せを組み合せて使用してもエラーとはならず正常に実行されます。
以下のように、複数行演算子と単一行副問合せを組み合せて使用してもエラーになりません。

副問合せの結果が0件の場合、主問合せにはNULL値が返されます。
副問合せでは、グループ関数を使用したりGROUP BY句を指定することができます。
▼複数行副問合せ
複数行副問合せとは、複数件のデータを返す副問合せです。
単一行副問合せと同じようにGROUP BY句を指定したり、副問合せをネストしたりすることができます。
また、複数列のデータを返すこともできます。
・複数行副問合せでは複数件のデータを返す
・複数行副問合せをネストすることができる
・複数行副問合せでは複数列のデータ返すことができる
副問合せでは、グループ関数を使用したりGROUP BY句を指定することができます。
▼インライン・ビュー
副問合せは、SELECT文のSELECT句、FROM句、WHERE句、HAVING句の他、INSERT文やUPDATE文等のDML文でも使用できます。
FROM句の副問合せはインライン・ビューとも呼ばれます。

関数の引数に別の関数を指定することを「関数のネスト」といいます
内部結合は、表の結合において結合条件を満たすデータのみを取り出す方法です。
▼次の作業のうち副問合せが必要な作業はどれですか(該当するものを全て選択して下さい)。
・全社員の平均給与を表示する
SELECT AVG(salary) FROM employees;
・全社員の平均給与より給与が多い従業員を表示する
SELECT employee_name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
・部署ごとの平均給与を表示する
SELECT AVG(salary) FROM employees GROUP BY department_id;
・所属従業員の給与の合計が一番多い部署の給与の合計を表示する
SELECT MAX(SUM(salary)) FROM employees GROUP BY department_id;
・全社員の平均給与より給与が少ない従業員を表示する
SELECT employee_name FROM employees WHERE salary < (SELECT AVG(salary) FROM employees);
▼Oracle DatabaseではSQL文の中に別のSQL文を入れ子にして実行することができ、
入れ子の内側の問合せのことを副問合せといいます(副問合せに対し、外側の問合せを主問合せといいます)。
通常の副問合せを使用したSQL文ではまず副問合せが実行され、副問合せの実行結果をもとに主問合せが実行されます。
副問合せの部分は()括弧で囲みます。(INSERT文で副問合せを使用してデータの追加を行う場合は、()は必須ではありません。
問題ID:19716の参考をご参照ください。)
上記では比較演算子の右辺に副問合せを記述していますが、副問合せを左辺に定義してもかまいません。
また、単一行副問合せの場合、比較演算子に複数行演算子を使用してもエラーにならず正常に実行されます。
しかし、複数行副問合せに単一行演算子を使用するとエラーとなります。
▼副問合せの後に主問合せを処理するとは限らない。
通常は副問合せ→主問合せの順に実行されますが、副問合せの中でそのFROM句に無い表を参照する(
副問合せの外側にある表を参照する)「相関副問合せ」では、主問合せで取り出される各行ごとに副問合せが実行されます。
(問題ID:20000の参考をご参照ください。)
副問合せは通常比較演算子の右辺に記述しますが、左辺に記述してもかまいません。
複合問合せにおいて、WHERE句、GROUP BY句、ORDER BY句等の使用は禁止されていません。
ただし、ORDER BY句を使用する場合には、以下のガイドラインに従います。
・ORDER BY句は複合問合せの最後の問合せに指定する
・ORDER BY句には最初の問合せに指定されている列名や列別名を指定する
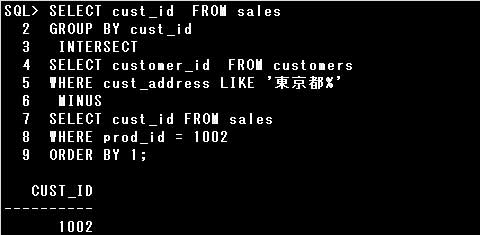
集合演算子は副問合せでも主問合せと同じように使用することができます。
▼INSERT文に副問合せ
INSERT INTO prod2
VALUES (1, (SELECT name FROM prod WHERE prodid = 1),
(SELECT category FROM prod WHERE prodid = 1), SYSDATE, NULL);
1つの列の1行のみ返す副問合せは、INSERT文のVALUES句の中でも使用できます。
設問のSQL文ではNAME列とCATEGORY列にそれぞれ1つの値を返す副問合せを使用しているため、正常に実行できます。

■DML文・DDL文・DCL文
データ操作言語(DML)文は、スキーマ・オブジェクトのデータにアクセスし変更や削除などの操作を行えますが、
オブジェクトの構造は変更しません。
SQL文の種類は次のとおりです。DML文の実行ではトランザクションは終了しません。

■IN、ANY、ALL演算子2
▼>ANY
ANY演算子はリスト内のいずれかの値が条件を満たす場合にTRUEを返しますので、
>ANY(値のリスト)は比較する値がリスト内のいずれかの値よりも大きい場合にTRUEを返します。
ANY演算子はリスト内の値のうち1つでも条件を満す値があればTRUEとなるので、
>ANY(値のリスト)はリスト内の最小値より大きい場合にTRUEとなるということです。
参考:
複数行演算子には次のものがあります。

複数行演算子ANYとALLは必ず単一行演算子とセットで使用しなければなりません。
また、IN演算子はNOT演算子と組合せて使用することができます。
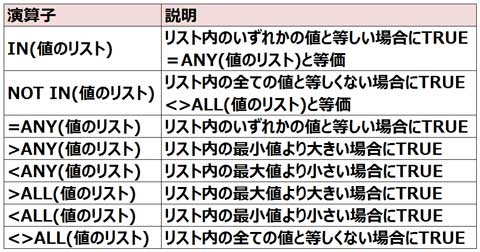
▼<ALL
ALL演算子はリスト内の全ての値が条件を満たす場合にTRUEをかえしますので、
<ALL(値のリスト)は比較する値がリスト内の全ての値よりも小さい場合にTRUEを返します。
ALL演算子はリスト内の全ての値が条件を満たさなければTRUEにならないため、
<ALL(値のリスト)はリスト内の最小値より小さい場合にTRUEになるということです。
=ALL(値のリスト)は値のリストの全ての値と一致した場合に条件がTRUEになりますが、
IN(値のリスト)は値のリストのいずれかに一致した場合に条件がTRUEになりますので、この2つの演算は等価ではありません。
=ANY(値のリスト)は値のリストのいずれか1つでも一致していれば条件がTRUEになりますので、IN(値のリスト)と等価です。
NOT IN(値のリスト)は値のリストのいずれにも一致しない場合に条件がTRUEになりますので、<>ALL(値のリスト)と等価です。
■排他ロック
▼排他ロック例)
ユーザーA:
SQL> SELECT d.department_name, e.employee_name
2 FROM departments d JOIN employees e USING (department_id)
3 FOR UPDATE OF e.employee_name NOWAIT; … ①
ユーザーB:
SQL> SELECT employee_id, employee_name FROM employees
2 FOR UPDATE NOWAIT; … ②
SQL> SELECT department_id, department_name FROM departments
2 FOR UPDATE NOWAIT; … ③
ユーザーA:
SQL> UPDATE employees SET salary = 350000 WHERE employee_id = 1020;
SQL> COMMIT;
①:SELECT文のFOR UPDATE句に OF 表名.列名 オプションが指定されています。
EMPLOYEES表のEMPLOYEE_NAMEが含まれる行にのみ排他ロックがかけられます。
②:①でユーザーAが排他ロックをかけているため、ユーザーBはSELECT文にFOR UPDATE句を指定しても排他ロックをかけることはできません。
さらにNOWAITオプションを指定しているので、SELECT文実行後、直ちにエラーとなります。
③:DEPARTMENTS表には排他ロックはかけられていないので、検索後該当する行が表示されます、
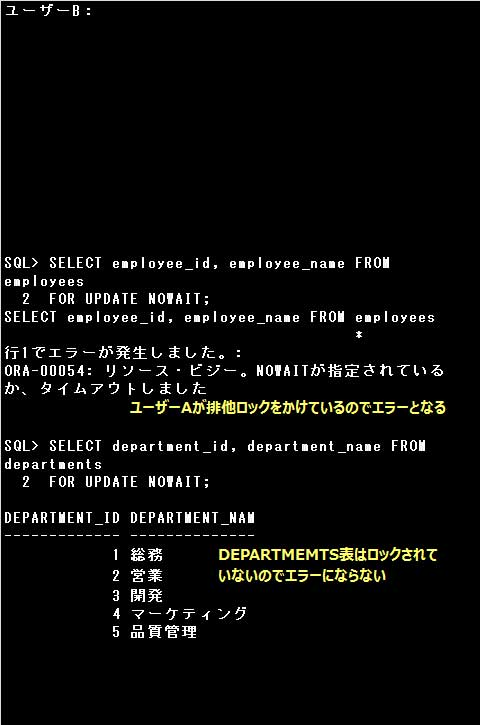
▼排他ロック例)
ユーザーA:
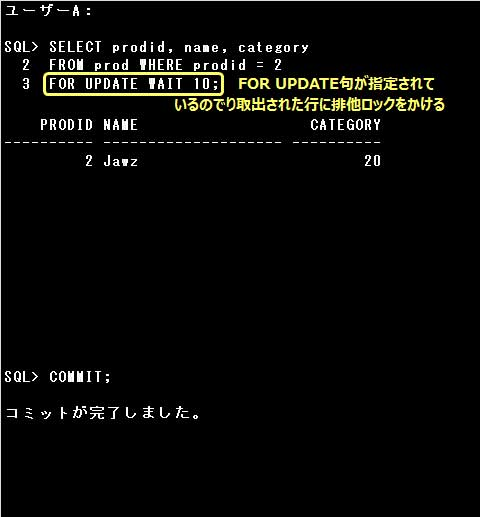
SQL> SELECT prodid, name, category FROM prod WHERE prodid = 2
2 FOR UPDATE WAIT 10; … ①
ユーザーB:
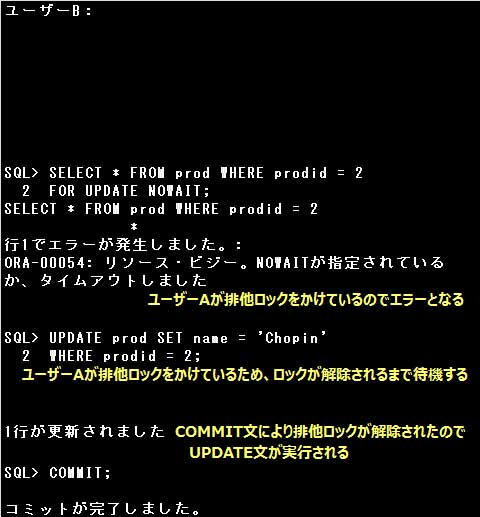
SQL> SELECT * FROM prod WHERE prodid = 2
2 FOR UPDATE NOWAIT; … ②
SQL> UPDATE prod SET name = ‘Chopin’ WHERE prodid = 2; … ③
ユーザーA:
SQL> COMMIT;
ユーザーB:
SQL> COMMIT;
①:SELECT文にFOR UPDATE句が指定されているので、SELECT文で取り出される行に排他ロックがかけられます。
②:①でユーザーAが排他ロックをかけているため、ユーザーBはSELECT文にFOR UPDATE句を指定しても排他ロックをかけることはできません。
さらにNOWAITオプションを指定しているので、SELECT文実行後、直ちにエラーとなります。
③:①でユーザーAが排他ロックをかけているため、ユーザーBがUPDATE文実行時、ユーザーAがかけた排他ロックが解除されるまで待機します。
■自動コミット・自動ロールバック
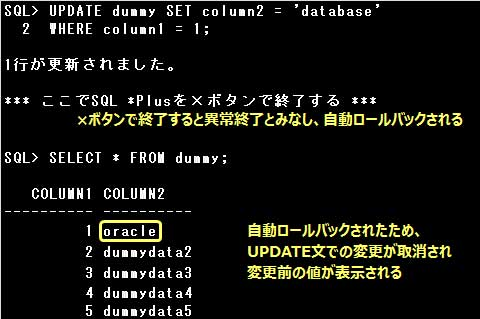
Oracle Databaseでは次の場合に自動ロールバックされます。
・システム障害が発生した場合
・SQL *Plusを×ボタンで終了した時など異常終了した場合
・EXIT文でSQL *Plus終了時
・DDL文実行時
これらの場合は自動コミットされます。
・SAVEPOINT文実行時
SAVEPOINT文ではトランザクション内にマーカーを作成しますが、トランザクションは終了しません
参考:
COMMIT文やROLLBACK文実行時以外でもトランザクションが終了する場合があります(暗黙的トランザクション処理)。
暗黙的トランザクション処理には、全ての処理を自動的に確定する自動コミットと、
全ての処理を自動的に取消す自動ロールバックの2種類があります。

[自動コミット]

[自動ロールバック]
▼排他ロック
ユーザーA:
1.SQL> INSERT INTO prod VALUES (11, ‘Debussy’, 10, SYSDATE, NULL);
2.SQL> COMMIT;
3.SQL> SELECT name FROM prod WHERE prodid = 11;
4.SQL> UPDATE prod SET name = ‘Liszt’ WHERE prodid = 11;
ユーザーB:
5.SQL> UPDATE prod SET name = ‘Chopin’ WHERE prodid = 11;
ユーザーC:
6.SQL> SELECT name FROM prod WHERE prodid = 11;
ユーザーA:
7.SQL> COMMIT;
ユーザーB:
8.SQL> SELECT name FROM prod WHERE prodid = 11;
9.SQL> COMMIT;
ユーザーA:
10.SQL> SELECT name FROM prod WHERE prodid = 11;
1.ユーザーAがINSERT文により、PROD表にデータが1件追加します。
ただし、INSERT文はDML文に該当し自動コミットされないため、データの追加は確定されていない状態です。
2.ユーザーAがCOMMIT文により、それまでの処理を確定します。
PROD表のPRODIDが11であるデータのNAME列の値は”Debussy”になります。
3.ユーザーAがSELECT文でPROD表のPRODIDが11であるデータを参照します。この時のNAME列の値は”Debussy”になります。
4.ユーザーAがUPDATE文により、PROD表のPRODIDが11であるデータのNAME列の値を変更します。
ただし、UPDATE文はDML文に該当し自動コミットされないため、データの変更は確定されていない状態です。
また、この時UPDATE文の対象の行に排他ロックがかかります。
5.ユーザーBがUPDATE文により、PROD表のPRODIDが11であるデータのNAME列の値を変更します。
ただし、PROD表のPRODIDが11である行は、ユーザーAの4.の操作で排他ロックがかかっているため、
4.の操作が確定されるまで待機させられます。
6.ユーザーCがSELECT文でPROD表のPRODIDが11であるデータを参照します。
この時のNAME列の値は4.、5.の変更が確定されていないので”Debussy”になります。
7.ユーザーAがCOMMIT文により、それまでの処理を確定します。この時、排他ロックは解除されます。
また、排他ロックが解除されたので、ユーザBの5.の操作が実行されます。
8.ユーザーBがSELECT文でPROD表のPRODIDが11であるデータを参照します。この時のNAME列の値は”Chopin”になります。
自身が行った変更は、確定前でも変更後のデータを参照できます。
9.ユーザーBがCOMMIT文により、それまでの処理を確定します。
PROD表のPRODIDが11であるデータのNAME列の値は”Chopin”になります。
10.ユーザーAがSELECT文でPROD表のPRODIDが11であるデータを参照します。
この時のNAME列の値は、ユーザーBの5.の変更が9.により確定されるので”Chopin”になります。
■INSERT文
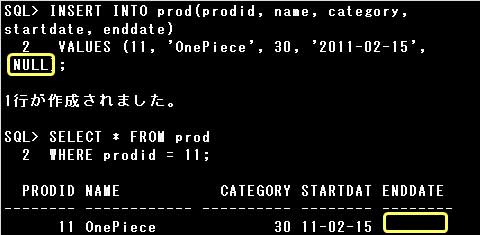
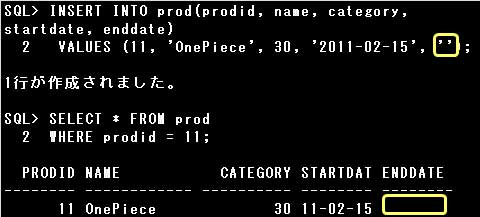
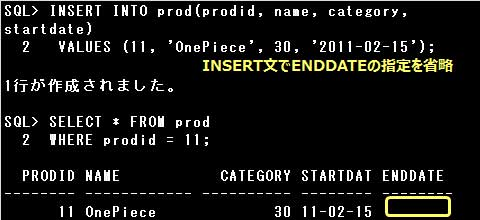
列にNULL値を登録するには、NULL値を登録する列に明示的にNULLまたは”(一重引用符を2つ)を指定するか、
INSERT文で列の指定を省略します。
NULL値の指定時、’NULL’としてしまうと文字列として判断されてしまいますので、注意しましょう。
▼正しい例)
▼エラー例)
・INSERT INTO prod2 VALUES SELECT prodid, name, category, startdate, enddate FROM prod;
副問合せを使用したINSERT文では、VALUES句は指定できません。
副問合せを使用したINSERT文では、VALUES句は使用できません。
INSERT句に指定する列のリストと、副問合せのSELECT句に指定する列のリストは同数かつ同じ順番で指定します。
また、INSERT句の列のリストは省略可能ですが、省略する場合、副問合せのSELECT句の列のリストには、
データを追加する表のすべての列を表の列構成の順番で指定しなければなりません
▼正しい例)
INSERT INTO prod2 SELECT * FROM prod;
INSERT INTO prod2(prodid, name, category) (SELECT prodid, name, category FROM prod);
■TIMESTAMP型
TIMESTAMP型はDATE型を拡張したデータ型で、世紀、年、月、日、時、分、秒に加え秒の小数点以下の値を格納することができます。
TIMESTAMP型の列に値を格納するためには、日付リテラルを使用するか、
文字列や数値をTO_TIMESTAMP関数でTIMESTAMP型の値に変換します。
暗黙的データ変換により、TIMESTAMP型の値をDATE型の列へ格納することができます。

■ALTER TABLE
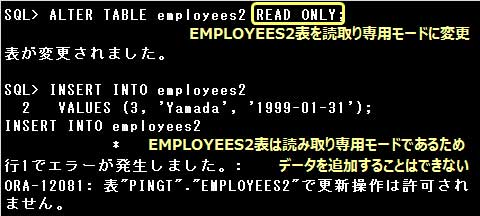
▼次のSQL文実行後、EMPLOYEES2表に実施できる行為はどれですか。
ALTER TABLE employees2 READ ONLY;
設問のSQL文を実行すると、EMPLOYEES2表は読取り専用モードに変更されます。
読取り専用モードの表では、データの追加、更新、削除はできませんが、表の削除は行うことができます。
既存の表の定義を変更するにはALTER TABLE文を使用します。
ALTER TABLE文では、次の操作を行うことができます。
・新しい列の追加
・既存の列のデータ型の変更
・既存の列へのデフォルト値の設定
・既存の列への制約の定義・制約追加
・既存の列の削除
・既存の列名の変更
・表のモード変更(読み取り/書き込みモード、読み取り専用モード)
▼FOREING KEY制約の削除
設問のPARENT表のID列は、CHILD表のDEPTID列からFOREIGN KEY制約(参照整合性制約とも呼ばれます)の親キーとして参照されています。
参照する側のデータ、子レコードが存在する場合、親レコードを削除しようとすると設問のエラーが発生します。
先に子レコードを削除するか、FOREIGN KEY制約を無効にすることで、親レコードを削除できるようになります。
もしくは、CHILD表のFOREIGN KEY制約にON DELETEオプションを指定して再作成し、親レコード削除時の処理を設定します。
ALTER TABLE文で既存の表の制約を無効化、もしくは有効化できます。
ALTER TABLE 表名 DISABLE | ENABLE CONSTRAINT 制約名;
↓↓↓FOREING KEY制約の削除SQL文
・ALTER TABLE child DISABLE CONSTRAINT dept_fk;
・DELETE FROM child WHERE deptid = 1;
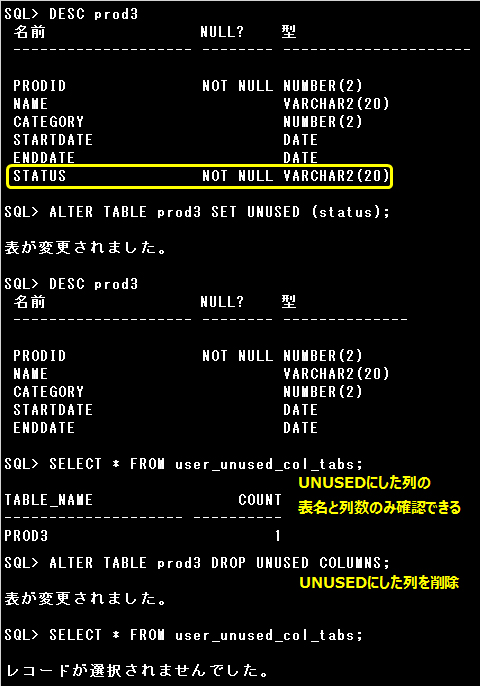
▼SET UNUSED句
ALTER TABLE文で既存の表の列を削除できますが、列の削除中は表にロックがかかり、列に多くのデータが含まれている場合は削除に時間がかかります。多くのユーザーがデータベースを利用する時間帯に負荷の高い削除処理を行いたくない場合、削除したい列にUNUSEDマークを設定して未使用にできます。
ALTER TABLE 表名 SET UNUSED ( 列名 [, 列名…]) [CASCADE CONSTRAINTS];
※1つの列のみUNUSEDにする場合は、次の構文も使用できます。
ALTER TABLE 表名 SET UNUSED COLUMN 列名 [CASCADE CONSTRAINTS];
UNUSEDに設定した列は、次のALTER TABLE文で削除します。データベースの負荷の低い時間帯に行えます。
ALTER TABLE 表名 DROP UNUSED COLUMNS;
SET UNUSED句に関しては、以下の注意事項があります。
・UNUSEDに設定した列は戻せず、DESCRIBEコマンドなどで列名やデータ型を確認できなくなる
・UNUSEDにした列に作成された索引や制約は削除される
・UNUSEDにした列と同じ名前の列を表に追加できる
・UNUSEDにした列の表名と列数は「USER_UNUSED_COL_TABS」ディクショナリで確認できる
・表に対して作成したシノニムの再作成は必要ない
・UNUSEDにした列を含むビューは無効になる
以上より、
・UNUSEDにした列の索引と制約は削除される
・UNUSEDにした列は、ALTER TABLE … DROP UNUSED COLUMNSコマンドで削除する
・UNUSEDにした列を含むビューは無効になる
UNUSED操作は取消しできません。
UNUSEDに設定した列は削除した列と同じ扱いになるので、SET UNUSED句を実行した直後から同じ名前の列を表に追加できます。
列をUNUSEDにする前の表に対して作成したシノニムは、再作成することなく正常にアクセスできます。
列をUNUSEDに設定して削除する例です。
■CREATE TABLE22
▼エラー例)
CREATE TABLE child
(
id NUMBER(2),
name VARCHAR2(10),
deptid NUMBER(2),
deptname VARCHAR2(10),
CONSTRAINT dept_fk FOREIGN KEY (deptid, deptname) REFERENCES parent (id, dept_name)
);
FOREIGN KEY制約で参照できる親表の列は、PRIMARY KEY制約またはUNIQUE制約が定義されている列だけです。
FOREIGN KEY制約の参照先にPRIMARY KEY制約またはUNIQUE制約が定義されていない列を指定するとエラーとなります。

▼OREIGN KEY制約
CREATE TABLE parent
(
id NUMBER(2) CONSTRAINT pid_pk PRIMARY KEY,
dept_name VARCHAR2(10)
);
CREATE TABLE child
(
id NUMBER(2) CONSTRAINT cid_pk PRIMARY KEY,
name VARCHAR2(10) CONSTRAINT cname_uq UNIQUE,
deptid NUMBER(2) CONSTRAINT dept_fk REFERENCES parent (id) ON DELETE CASCADE
);
INSERT INTO parent VALUES (1, ‘parent’);
INSERT INTO child VALUES (10, ‘child’, 1);
この後、正常に実行できるSQL文はどれですか。
DELETE FROM parent;
PARENT表はCHILD表のFOREIGN KEY制約(参照整合性制約とも呼ばれます)の親表として参照されています。
この場合、参照されている行がない場合でも、子表よりも先に親表を削除できません。DROP TABLE文はエラーとなります。
しかしデータの削除に関しては、FOREIGN KEY制約にON DELETEオプションを指定することによって、
親表の行を削除した場合に子表の行をどのようにするかを指定できます。

設問のCHILD表のFOREIGN KEY制約には「ON DELETE CASCADE」が指定されているので、
PARENT表の行を削除すると子表の行も削除されます。よって、DELETE文は正常に実行できます。
TRUNCATE TABLE文に関しては、データが存在した場合は、FOREIGN KEY制約の親表を切り捨てることはできません。
Oracle Databaseでは、次の制約を定義することができます。
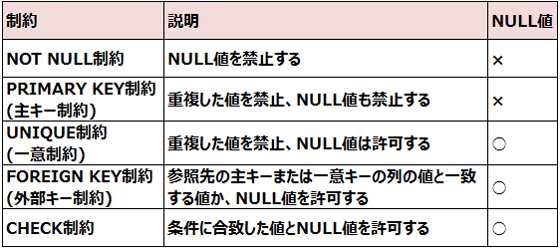
UNIQUE制約が定義されている列にNULL値を格納できる
FOREIGN KEY制約が定義されている列にNULL値を格納できる
CHECK制約に指定できる条件にはいくつかの制限があります。CURRVAL,NEXTVAL,LEVEL,ROWNUM疑似列の参照はできません。
表の作成時、PRIMARY KEY制約は必ず指定する必要はありません。
NOT NULL制約は列レベルでしか定義することができません。
▼エラー例)
・CREATE TABLE sales2
AS
SELECT prod_id, cust_id, sysdate FROM sales;
副問合せのSELECT句に計算式や関数を指定する場合は、計算式や関数に列別名を指定するか、
CREATE TABLE文で列名を指定しなければなりません。
副問合せのSELECT句にSYSDATE関数が使用されていますが、SALES2表に列名は指定されておらず、
副問合せでもSYSDATE関数に列別名が指定されていないためエラーとなります。
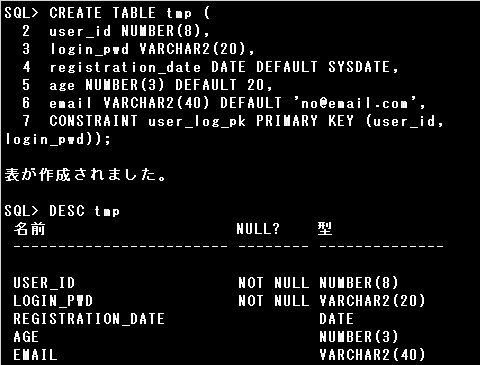
▼次の要件を満たす表を作成するには、どのSQL文を実行しますか(2つ選択して下さい)。
・USER_IDはサイズ8の数値型で、NULL値を入力できない
・LOGIN_PWDは文字型で、NULL値を入力できない
・USER_ID, LOGIN_PWDの組み合せは一意でないといけない
・REGISTRATION_DATEは日付型で、デフォルト値は当日の日付
・AGEはサイズ3の数値型で、デフォルト値は20
・EMAILは文字型で、デフォルト値は「no@email.com」
▼エラー例)
・CREATE TABLE tmp (
user_id NUMBER(8) CONSTRAINT user_nn NOT NULL,
login_pwd VARCHAR2(20) CONSTRAINT login_nn NOT NULL,
registration_date DATE DEFAULT = SYSDATE,
age NUMBER(3) DEFAULT = 20,
email VARCHAR2(40) DEFAULT = ‘no@email.com’,
CONSTRAINT user_log_uk UNIQUE (user_id, login_pwd));
列のデフォルト値は「列名 データ型 DEFAULT 値」の書式で記述します。等号=は不要なのでエラーとなり、誤ったSQL文です。
▼正しい例)
・CREATE TABLE tmp (
user_id NUMBER(8) CONSTRAINT user_nn NOT NULL,
login_pwd VARCHAR2(20) CONSTRAINT login_nn NOT NULL,
registration_date DATE DEFAULT SYSDATE,
age NUMBER(3) DEFAULT 20,
email VARCHAR2(40) DEFAULT ‘no@email.com’,
CONSTRAINT user_log_uk UNIQUE (user_id, login_pwd));
USER_IDとLOGIN_PWDに列レベルでNOT NULL制約を定義し、表レベルで両方の列にUNIQUE制約を定義しています。
各列のデフォルト値も正しく設定されており、正しいSQL文です。

▼エラー例)
・CREATE TABLE tmp (
user_id NUMBER(8),
login_pwd VARCHAR2(20),
registration_date DATE DEFAULT SYSDATE,
age NUMBER(3) DEFAULT 20,
email VARCHAR2(40) DEFAULT ‘no@email.com’,
CONSTRAINT user_nn NOT NULL (user_id),
CONSTRAINT login_nn NOT NULL (login_pwd),
CONSTRAINT user_log_uk UNIQUE (user_id, login_pwd));
表レベルでNOT NULL制約を定義していますが、NOT NULL制約は列レベルでしか定義できません。エラーとなり、誤ったSQL文です。
▼正しい例)
・CREATE TABLE tmp (
user_id NUMBER(8),
login_pwd VARCHAR2(20),
registration_date DATE DEFAULT SYSDATE,
age NUMBER(3) DEFAULT 20,
email VARCHAR2(40) DEFAULT ‘no@email.com’,
CONSTRAINT user_log_pk PRIMARY KEY (user_id, login_pwd));
PRIMARY KEY制約を定義すると、定義された列または列の組合せに重複したデータやNULL値を登録できなくなります。
設問の条件を満たしているため、正しいSQL文です。
▼エラー例)
・CREATE TABLE tmp (
user_id NUMBER(8) CONSTRAINT user_nn NOT NULL, CONSTRAINT user_uk UNIQUE,
login_pwd VARCHAR2(20) CONSTRAINT login_nn NOT NULL, CONSTRAINT login_uk UNIQUE,
registration_date DATE DEFAULT SYSDATE,
age NUMBER(3) DEFAULT 20,
email VARCHAR2(40) DEFAULT ‘no@email.com’);
1つの列に複数の列レベル制約を定義する場合はスペースで区切りますが、「,」で区切っているのでエラーとなります。
また、複数の列の組合せにUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。誤ったSQL文です。
列の組合せに対してPRIMARY KEY制約を定義する場合は、表レベルで定義しなければなりません。
CHECK制約はWHERE句で指定できる条件と同様の指定ができますが、SYSDATE関数を使用できない等いくつかの制限があります。
CHECK制約の条件にはWHERE句で指定できる条件と同様の指定ができます。BETWEEN演算子も使用することができます。
FOREIGN KEY制約は列レベル、表レベルのどちらでも定義することができます。
列の組合せに対してFOREIGN KEY制約を定義する場合は、表レベルで定義します。
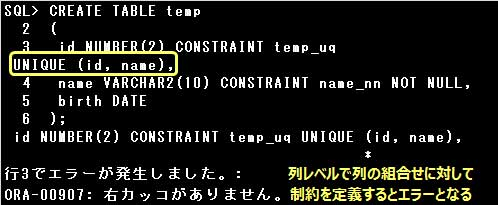
▼エラー例)
CREATE TABLE temp
(
id NUMBER(2) CONSTRAINT temp_uq UNIQUE (id, name),
name VARCHAR2(10) CONSTRAINT name_nn NOT NULL,
birth DATE
);
CREATE TABLE temp
(
id NUMBER(2) CONSTRAINT id_uq UNIQUE,
name VARCHAR2(10) CONSTRAINT name_nn NOT NULL,
birth DATE,
CONSTRAINT temp_uq UNIQUE
);
UNIQUE制約は列レベル、表レベルのどちらでも定義することができますが、
複数の列の組合せに対してUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。
また、表レベルで制約を定義する場合は、制約を定義する列を指定しなければなりません。

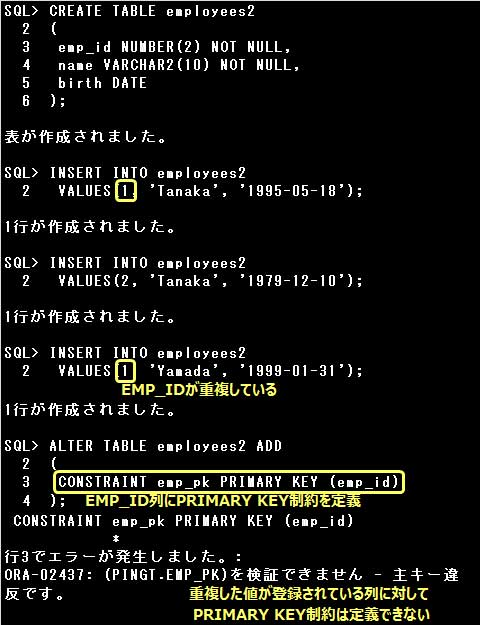
EMPLOYEES2表のEMP_ID列には重複した値のデータが登録されています。
PRIMARY KEY制約が定義された列には重複したデータやNULL値は格納できませんので、
EMP_ID列にはPRIMARY KEY制約を定義することはできません。
既にデータが登録されている表に後から制約を追加する事はできますが、登録されているデータが
追加する制約の条件を満たしている必要がありますので注意して下さい。

■順序 2
順序はCREATE SEQUENCE文で作成し、ALTER SEQUENCE文で変更、DROP SEQUENCE文で削除します。
作成した順序から新しい順序値を取得したり、現在の順序値を確認するためには、NEXTVAL疑似列、
CURRVAL疑似列を参照します。ただし、CURRVAL疑似列は、
順序生成後に一度NEXTVAL疑似列を参照してから参照しなければなりません。
・順序を削除する場合は、DROP SEQUENCE文で削除する
・セッション開始後、CURRVAL疑似列を参照する前にNEXTVAL疑似列を参照しなければならない
・順序は表と関連付けられるものではないので、複数の表で1つの順序を使用できます。
・順序値がキャッシュされている状態の時にシステムがクラッシュすると、メモリ上にキャッシュされている順序値は
失われてしまい、データベース再起動後も復帰はしません。そのため、順序値に欠番が生じることになります。
・ALTER SEQUENCE文で最大値の変更は可能です。後から変更できないのは初期値です。
■シノニム
プライベートシノニムはCREATE SYNONYM権限を持つユーザーによって作成されます。
プライベートシノニムは、CREATE SYNONYM文によって作成されます。
▼例)
・CREATE SYNONYM dept FOR departments;
・CREATE PUBLIC SYNONYM dept FOR departments;
CREATE SYNONYM文にPUBLICオプションを指定すると、パブリックシノニムが作成されます。
▼エラー例
・CREATE PRIVATE SYNONYM dept FOR departments;
CREATE SYNONYM文にPRIVATEオプションはありません。
▼シノニムを削除した場合、シノニムが参照していた表自体に影響はありません。
また、シノニムが作成されている表を削除しても、シノニムは削除されません。
ビューなど、他のオブジェクトに対してもシノニムを作成できます。
パブリックシノニムを作成しても、その表に対する参照権限がなければ表からデータを取り出せません。
自身が所有する表に対してもシノニムを作成できます。
■索引
索引はデータの検索を高速化するスキーマ・オブジェクトです。
表の列に索引が設定されると、索引が設定された列の値と、その物理的な格納場所(ROWID)を登録します。
索引が設定されていない表でデータを検索する場合、問合せの条件に従って、
表の先頭のデータから1行ずつ検索していきますので、データが大量にある場合には相当の時間がかかります。
しかし索引を設定している表では、ROWIDを使用してデータを検索するため、
大量のデータの中からでも高速に目的のデータを探すことができます。
また、表に対してDML文を実行する度に、表に設定された索引はメンテナンス(必要であれば更新)されます。
以上より、
・表のデータへのアクセスを高速化する
・索引を設定している表ではROWIDを使用して検索する
・DML文実行時、索引がメンテナンスされる
FOREIGN KEY制約定義時、自動的に制約は作成されません。PRIMARY KEY制約またはUNIQUE制約の定義時に一意索引が自動的に作成されます。
索引を設定している表を削除すると、設定されている索引は自動で削除されます。
列の組合せに索引を作成することもできます。
■ビュー
ビューを利用する目的は次の通りです。
・データへのアクセス制御
・複雑なSQL文の簡素化
・データの独立性を確保
・同じデータを異なる視点で表示
※ビューを利用しても、問合せのパフォーマンスが向上することはない。
参考:
ビューとは、1つまたは複数の表や他のビューを基にして作成する仮想的な表のことです。
ビューには実データは含まれません。ビューに対する問合せを実行すると、
Oracleサーバーは、ビューの基となっている実表へ問い合わせ処理を行います。
ビューを利用する目的は次の通りです。
[データへのアクセス制御]
ビューに対するSELECT文では、ビューに定義されている列にしかアクセスできません。
表の一部の列の値をユーザーに参照させたくない場合などに、参照させたくない列を除いたビューを作成し、
適切な権限を与えることで、データアクセスを制限することができます。
[複雑なSQL文の簡素化]
複数の表を結合して複雑な問合せを行う場合、予めその問合せでビューを作成しておくと、
複雑な問合せを毎回行う必要はなく、ビューに対して問合せを行うことで、目的のデータを取り出すことが可能になります。
[データの独立性を確保]
ビューの基となっている実表の定義に変更があった後でも、ビューに定義されている列に変更がなければ、
変更前と同様にビューにアクセスすることができます。
[同じデータを異なる視点で表示]
ある表からデータを取り出す場合、所属する部署や役職など、データを取り出すユーザーによって必要な情報が異なります。
それぞれの視点でビューを作成しておくと、同じデータを異なる視点で表示できます。
ビューには、単一ビューと複合ビューの2種類のビューがあります。

▼USER_CONS_COLUMNSビュー
USER_CONS_COLUMNSビューは、ビューにアクセスするデータベースユーザーが所有していて、
制約が定義されている列を表示するデータ・ディクショナリ・ビューです。
データ・ディクショナリ・ビューとは、データベース内のオブジェクトやユーザー、
権限などに関する様々な情報が格納されているが直接アクセスできないデータ・ディクショナリ表を参照するためのものです。
・ユーザー所有の、制約が定義されている列を表示する
▼ALL_CONS_COLUMNSビュー
・ユーザーがアクセスできる、制約が定義されている全ての列を表示する
▼USER_CONSTRAINTSビュー
・ユーザー所有の表の制約を表示する
▼ALL_CONSTRAINTSビュー
・ユーザーがアクセスできる表の制約を表示する
■データ型
CHAR型は最大2,000バイトまでの文字データを格納できる固定長のデータ型です。
CHAR(5)に「abc」が格納されると、データの末尾に空白を追加し、長さが5バイトの「abc 」を格納します。
また、LONG型は最大2GBまでの文字データを格納できる可変長のデータ型ですが、次のような制約があります。
・LONG型の列は1つの表に1つだけ定義できる
・LONG型の列には制約は定義できない(NULLおよびNOT NULL制約を除く)
・LONG型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG型の列はコピーできない

VARCHAR2型のデータサイズの指定は省略できません。
BFILE型は最大4GBまでのバイナリデータを格納できる、読み取り専用のデータ型です。
データはOracleのデータファイル内ではなく、OS上にバイナリファイル(動画やイメージ)として格納され、
ファイルに対するポインタ情報のみが格納されます。
▼バイナリデータを扱う主なデータ型は次の通りです。

なお、LONG RAW型はLONG型と同様に以下の制限があります。
・LONG RAW型の列は1つの表に1つだけ定義できる
・LONG RAW型の列には制約は定義できない
・LONG RAW型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG RAW型の列はコピーできない
■スキーマ・オブジェクト
スキーマ・オブジェクトとはデータベースに格納する表やビュー、索引などの総称で特定のユーザーに所有されるものです。
記憶域やロール、ユーザー等システム全体で共有されるものはスキーマ・オブジェクトではありません。
以上より、
・表
・ビュー
・シノニム
・索引
・順序
参考:
データベースに格納できる表やビューなどを総称してデータベース・オブジェクトと言います。
データベース・オブジェクトは必ずいずれかのユーザーに所有されており、スキーマ・オブジェクトとも呼ばれます。
主なスキーマ・オブジェクトは以下のとおりです。

スキーマとは、オブジェクトの所有者を表す論理的な概念です。
データベースのユーザーは必ず1つのスキーマを所有し(スキーマ名はユーザー名と同じ名前になります)、
ユーザーが作成したオブジェクトは、そのユーザーが所有するスキーマに格納されます。
ユーザーは別のユーザーが所有しているオブジェクトを参照することもできますが、その場合は、
スキーマ名.オブジェクト名
のように、オブジェクト名の前にスキーマ名をつけて、どのスキーマのオブジェクトを参照するのかを指定しなければなりません。
自分自身が有するオブジェクトを参照する場合には、スキーマ名を省略することができます。
スキーマ名を省略した場合は、ログインしているユーザーのスキーマ内のオブジェクトを参照します。