■JOIN句について
エラー例)SELECT department_name, employee_name, salary FROM departments d JOIN employees e WHERE d.department_id = e.department_id;
JOIN句で結合する場合、結合条件はON句、またはUSING句に記述します。
このSQL文のように等号(=)を使用するならばON句が必要ですが、WHERE句に結合条件が指定されておりエラーとなります。
JOIN句による結合では、結合条件をON句に記述しなければなりません。
USING句による結合で選択条件を追加する場合、WHERE句を使用します。
JOIN句とON句は1対1で記述します。選択条件を追加する場合は、WHERE句または論理演算子ANDで指定します。
■自然結合について
自然結合では、結合列に表接頭辞を使用することはできません。表接頭辞を指定するとエラーとなります。
自然結合では3つ以上の表も結合することができます。
自然結合では、2つの表に共通して存在する同名で同じデータ型(または互換性のあるデータ型)の列に基づいて、表を結合します。
結合列以外の列には、表接頭辞の使用しても使用しなくても構いません。
ただし、表接頭辞を使用するとパフォーマンスが向上します。
自然結合では、結合する列が自動的に判断されるため、明示的に結合条件を指定する必要がありません
2つの表に同名で異なるデータ型の列がある場合、自然結合を行うとエラーとなります。
同名で同じデータ型(または互換性のあるデータ型)の列が2つ以上ある場合には、全ての共通する列が結合条件として使用されます。
いずれか1つの列を結合列として指定することはできません。
NATURAL JOIN句では結合する列が自動的に判断されるため結合条件の記述は必要ありませんが、
JOIN句の場合はUSING句やON句で結合条件を記述する必要があります。
USING句を指定した結合では、結合列に表接頭辞を使用することはできません。
■外部結合演算子(+)について
エラー例)SELECT emp.employee_name, mgr.employee_name FROM employees emp, employees mgr WHERE emp.manager_id(+) = mgr.employee_id(+);
Oracle Databaseでは外部結合演算子(+)を使用して外部結合を行うこともできます。外部結合演算子(+)を用いた結合では、
WHERE句に指定した条件の片側に外部結合演算子(+)を指定します。
なお、外部結合演算子(+)を用いた外部結合では、WHERE句の両側に外部結合演算子(+)を指定することはできません。両方に指定した場合はエラーとなります。
Oracle独自の結合構文で外部結合を行う場合、外部結合演算子(+)を使用します。条件の左側に(+)をつけると右側外部結合、
右側につけると左側外部結合の結果と等しくなります。
▼左側外部結合となり、LEFT JOINと同じとなる
左側外部結合 例)
SELECT emp.employee_name, mgr.employee_name
FROM employees emp, employees mgr
WHERE emp.manager_id = mgr.employee_id(+);
▼右側外部結合となり、RIGHT JOINと同じとなる
右側外部結合 例)
SELECT emp.employee_name, mgr.employee_name
FROM employees emp, employees mgr
WHERE emp.manager_id(+) = mgr.employee_id;
■CROSS JOINについて
CROSS JOINキーワードで表の結合を行うと、2つの表に登録されている行の全ての組合せ(デカルト積といいます)を返すクロス結合が行われます。
クロス結合では、2つの表に登録されている行の全ての組合せが返されるので、結合条件の指定はできません。
CROSS JOIN 例)
SELECT d.department_name, e.employee_name
FROM departments d CROSS JOIN employees e;
■等価結合について
等価結合では、結合する2つの表の特定列の値が等しい行だけを結合してデータを取り出します。
等価結合を行うには次の方法があります。
・自然結合(NATURAL JOIN)
・USING句を使用した結合
・ON句を使用した結合
・Oracle独自の結合構文による結合
■外部結合について
結合条件を満たしたデータのみを取り出すのではなく、検索条件を満たしていないデータも一緒に取り出す方法を外部結合といいます。
Oracle独自の結合構文では外部結合演算子(+)を使用して外部結合を行えますが、完全外部結合は行えません。
結合条件を満たす行のみを取り出す結合を内部結合といいます。
■自己結合について
▼エラー例)自己結合でON句なしのため、全ての組合せデカルト積の出力となる。
・SELECT DISTINCT p1.prod_name, p2.list_price
FROM new_products p1, new_products p2
WHERE p1.prod_name <> p2.prod_name
ORDER BY 2;
・Oracle独自の結合構文による自己結合ですが、WHERE句に結合条件(p1.list_price = p2.list_price)を記述していないため、
行の全ての組合せのデカルト積が返されます。誤ったSQL文です。
▼エラー例)副問合せでWHERE句にグループ関数を使用してエラーとなる。
・SELECT prod_name, list_price FROM new_products
WHERE list_price IN (SELECT list_price FROM new_products GROUP BY list_price)
AND COUNT(list_price) > 1
ORDER BY 2;
副問合せを使用していますが、WHERE句にグループ関数を記述しているためエラーとなります。誤ったSQL文です。
・副問合せは、SELECT文のSELECT句、FROM句、WHERE句、HAVING句の他、INSERT文やUPDATE文等のDML文でも使用できます。
・FROM句の副問合せはインライン・ビューとも呼ばれます。
■USING句について
結合する2つの表に同じ列名でデータ型の異なる列がある場合、USING句を使用する。
結合する2つの表の一部の列を結合列として使用する場合、USING句を使用する。
USING句を使用した結合は、等価結合の1つで、結合列を明示的に指定することができるので、
2つの表に同名の列が複数あり、その一部を結合列にしたい場合や、同名でデータ型の異なる列がある場合に、
USING句で結合列に指定しないことで、エラーを回避できます
(自然結合では、同名でデータ型が異なる列を結合してしまいエラーとなります)。
USING句を使用した結合は等価結合となります。
[USING句]
・等価結合の場合のみに使用できる
・2つの表で同名の列のみ結合列として使用できる
・結合列に表接頭辞を使用できない
USING句を使用した結合では、結合列、SELECT句、WHERE句で表接頭辞を使用するとエラーとなる。
■ON句について
ON句を使用した表の結合において、結合する2つの表の両方に同名の列がある場合、
同名の列をSELECT句やWHERE句に指定する場合には表接頭辞を付加して指定しなければなりません。
エラー例)
SELECT category, name
FROM category
JOIN prod ON category.category = prod.category;
USING句とON句の違いは次のとおりです。
・USING句は等価結合にのみ、ON句は等価結合と非等価結合に使用できる
・USING句は同名の列のみ、ON句は異なる列名の列も結合列に使用できる
・USING句では結合列に表接頭辞を使用できないが、ON句では結合列に表接頭辞を必ず使用する
USING句では結合列に表接頭辞を使用するとエラーとなります。ON句では結合列に表接頭辞を使用しないとエラーとなります。
[ON句]
・等価結合,非等価結合の両方に使用できる
・2つの表で異なる列名の列も結合列として使用できる
・結合列に表接頭辞を必ず使用する
■FULL JOINとCROSS JOINの違いについて
クロス結合は、2つのテーブル間にデカルト積を生成し、すべての行のすべての可能な組み合わせを返します。
onすべてをすべてに結合しているだけなので、条項はありません。
full outer joinはleft outer joinとright outer joinの組み合わせです。クエリのwhere句に一致する両方のテーブルのすべての行を返します。
これらの行でon条件が満たされない場合はnull行となる。
参考サイト:https://qastack.jp/programming/3228871/sql-server-what-is-the-difference-between-cross-join-and-full-outer-join
■IN、ANY、ALL演算子について
=ANY(値のリスト)はリスト内のいずれかの値と等しい場合にTRUEとなります。IN(値のリスト)と等価です。
=ALL(値のリスト)はリスト内の全ての値と等しい場合にTRUEとなります。
>ANY(値のリスト)はリスト内の最小値よりも大きい場合にTRUEとなります。
<>ALL(値のリスト)はリスト内の全ての値と等しくない場合にTRUEとなります。NOT IN(値のリスト)と等価です。

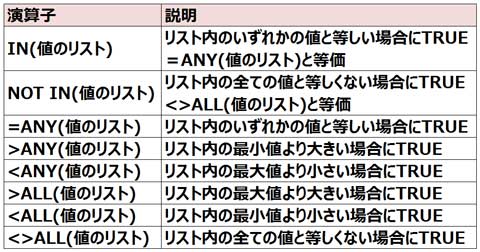
IN(値のリスト)はリスト内のいずれかの値と等しい場合にTRUEとなります。
=ALL(値のリスト)は値のリストの全ての値と一致した場合に条件がTRUEになります。
IN(値のリスト)は値のリストのいずれかに一致した場合に条件がTRUEになります
■複数行演算子・単一行演算子について
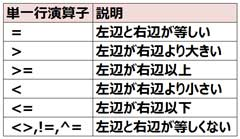
・IN演算子は単一行副問合せでも使用できます。単一行副問合せに複数行演算子を使用してもエラーにならず正常に実行されます。
・単一行副問合せとANY演算子を組み合せて使用できる
・単一行副問合せとIN演算子を組み合せて使用できる
・副問合せの結果が0件の場合、主問合せにはNULL値が返されます。
・副問合せでは、グループ関数を使用したりGROUP BY句を指定することができます。
■副問合せ
副問合せはネストすることができます。WHERE句に指定する副問合せでは最大255レベルまでのネストが可能です。
ネストした問合せでは、内側の問合せから実施されます。
副問合せの条件が一致しない場合、副問合せは主問合せにNULL値を返します。
副問合せからNULL値が返されると、主問合せはエラーとはならず、データを1件も表示しません。
内側の問合せが複数件のデータを返す場合、単一行演算子を使用している場合、エラーとなる。
複数行副問合せとは、複数件のデータを返す副問合せです。
単一行副問合せと同じようにGROUP BY句を指定したり、副問合せをネストしたりすることができます。
また、複数列のデータを返すこともできます。
副問合せでは、グループ関数を使用したり、GROUP BY句を指定することができる。
副問合せの部分は()括弧で囲みます。(INSERT文で副問合せを使用してデータの追加を行う場合は、()は必須ではありません。)
副問合せを右辺、左辺のどちらにに定義してもかまいません。
単一行副問合せの場合、比較演算子に複数行演算子を使用してもエラーにならず正常に実行されます。
しかし、複数行副問合せに単一行演算子を使用するとエラーとなります。
通常は副問合せ→主問合せの順に実行されますが、副問合せの中でそのFROM句に無い表を
参照する(副問合せの外側にある表を参照する)「相関副問合せ」では、
主問合せで取り出される各行ごとに副問合せが実行されます。
▼副問合せのTBLを副問合せで作成している珍しいケース
SELECT p.prod_name, s.qty_sold
FROM (SELECT prod_id, SUM(quantity_sold) qty_sold FROM sales GROUP BY prod_id) s
RIGHT OUTER JOIN products p
ON s.prod_id = p.prod_id;
・部署が3の部署の最高給与を表示する
SELECT MAX(salary) FROM employees WHERE department_id = 3;
・「山口洋子」と同じ部署の従業員を表示する
SELECT department_id, employee_name FROM employees
WHERE department_id = (SELECT department_id FROM employees WHERE employee_name = ‘山口洋子’);
・給与が40万円以上の従業員の平均給与を表示する
SELECT AVG(salary) FROM employees WHERE salary >= 400000;
・従業員とその上司の名前を表示する
SELECT e.employee_name, m.employee_name FROM employees e LEFT OUTER JOIN employees m
ON e.manager_id = m.employee_id;
・入社日が2001年10月より前で上司のいない従業員を表示する
SELECT employee_name, hiredate FROM employees
WHERE hiredate < ’01-10-01′ AND manager_id IS NULL;
・副問合せでは、GROUP BY句を指定して2レベルまでグループ関数をネストしているので問題ありません。
・PROD表のCATEGORY列が”NULL”である行もありますが、NULL値同士を判定してもNULL値となり、
値が等しいという判定ができないので、CATEGORY列が”NULL”である行は取り出されません。
WHERE句に指定された副問合せがNULL値を戻した場合、主問合せの結果は0件になります。
ただし、IN演算子の場合は、リスト内のいずれかの値と等しい場合にTRUEを返すため、IN演算子の値のリストに
NULL値が含まれていても、NULL値以外の値と比較対象の値が等しければ、主問合せでデータが取り出されます。
NOT IN演算子の場合は、リスト内の全ての値と等しくない場合にTRUEを返しますが、NOT IN演算子の値のリストにNULL値が含まれていると、
NULL値と比較対象の値の比較結果がNULL値になるので、全ての値と等しくないという判定がなされません。
そのため、主問合せではデータが1件も取り出されません。
・副問合せは、SELECT文のSELECT句、FROM句、WHERE句、HAVING句、ORDER BY句の他、INSERT文や
UPDATE文等のDML文でも使用することができます。
副問合せには、次のようにいろいろな使用方法があります。
・SELECT文のSELECT句、FROM句、WHERE句、HAVING句、ORDER BY句や、INSERT文、UPDATE文等のDML文で使用できる
・主問合せと副問合せで異なる表にアクセスできる
・1つの主問合せに対し、複数の副問合せを指定できる
・副問合せをネストできる(WHERE句に指定した副問合せでは255レベルのネストが可能)
・副問合せの中でGROUP BY句やHAVIMG句、ORDER BY句を使用できる
・副問合せがデータを1件も返さない場合は、主問合わせにNULLを返す
■順序について
・順序を削除する場合は、DROP SEQUENCE文で削除する
・セッション開始後、CURRVAL疑似列を参照する前にNEXTVAL疑似列を参照しなければならない
・順序はCREATE SEQUENCE文で作成し、ALTER SEQUENCE文で変更、DROP SEQUENCE文で削除します。
・作成した順序から新しい順序値を取得したり、現在の順序値を確認するためには、NEXTVAL疑似列、CURRVAL疑似列を参照します。
ただし、CURRVAL疑似列は、順序生成後に一度NEXTVAL疑似列を参照してから参照しなければなりません。
・順序は表と関連付けられるものではないので、複数の表で1つの順序を使用できます。
・順序値がキャッシュされている状態の時にシステムがクラッシュすると、メモリ上にキャッシュされている順序値は、
失われてしまい、データベース再起動後も復帰はしません。
そのため、順序値に欠番が生じることになります。
・ALTER SEQUENCE文で最大値の変更は可能です。後から変更できないのは初期値です。
・欠番が発生する場合もある
・複数のユーザーで共有可能である
・1つの順序を複数の表で使用できる
・順序は、指定した規則に従って一意の番号を自動的に生成するスキーマ・オブジェクトです。
順序は主に重複したデータを受け付けない、PRIMARY KEY制約が定義された列の値を生成する際に利用されます。
・順序は複数のユーザーで共有可能なため、複数のユーザーが同じ順序で順序値を生成した場合、常に全体を通して一意な順序値が生成されます。
また、順序は表と関連付けられるものではないので、複数の表で1つの順序を使用することもできます。
・順序は指定された規則に従って一意な順序値を生成しますが、ロールバックが発生した時などには欠番が生じることもあり、
連番が保証されているわけではありません。
増分値を指定することができる
初期値のデフォルト値は1である
▼順序を指定する際に指定可能なオプションは、下記の通りである。
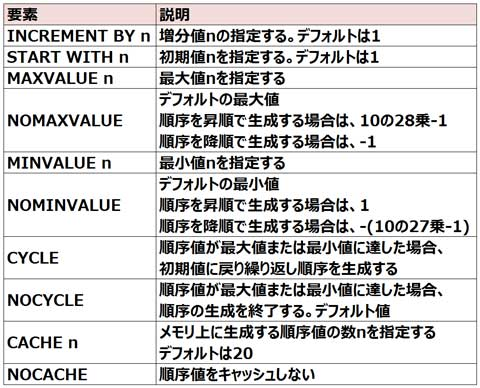
・順序値が最大値に達した場合、初期値に戻って順序値を生成するか、順序値の生成を終了するかをCYCLE/NOCYCLEオプションで指定することができます。
・CURRVAL疑似列を参照すると、最後に生成された順序値が返されます。その際に順序値は生成されません。
・順序の増分値に負の値を指定することもできます。
・シノニムを削除した場合、シノニムが参照していた表自体に影響はありません。
また、シノニムが作成されている表を削除しても、シノニムは削除されません。
・表やビューなど、他のオブジェクトに対してもシノニムを作成できます。
・パブリックシノニムを作成しても、その表に対する参照権限がなければ表からデータを取り出せません。
・自身が所有する表に対してもシノニムを作成できます。
▼NEXTVAL疑似列、CURRVAL疑似列は以下では使用できません。
・SELECT文、UPDATE文、DELETE文内の副問合せ
・ビューのSELECT句
・DISTINCTキーワードが指定されたSELECT文
・GROUP BY句、ORDER BY句、HAVING句を持つSELECT文
・集合演算子UNION、INTERSECT、MINUSによって別のSELECT文と結合されているSELECT文
・SELECT文のWHERE句
・CHECK制約の条件
・Oracle 12cより、CREATE TABLE文やALTER TABLE文のデフォルト値にNEXTVAL疑似列とCURRVAL疑似列を指定できるようになりました。
・順序作成後、NEXTVAL疑似列を参照せずにCURRVAL疑似列を参照するとエラーとなりますが、
CURRVAL疑似列を参照せずにNEXTVAL疑似列を参照してもエラーとはなりません。
また、NEXTVAL疑似列を参照せずにCURRVAL疑似列をCREATE TABLE文のデフォルト値として指定できます。
・1つの列にデフォルト値とPRIMARY KEY制約を同時に定義できます。
■シノニムについて
・プライベートシノニムはCREATE SYNONYM権限を持つユーザーによって作成されます。
・プライベートシノニムは、CREATE SYNONYM文によって作成されます。
▼プライベートシノニムを作成するSQL
CREATE SYNONYM dept FOR departments;
CREATE SYNONYM文にPUBLICオプションを指定すると、パブリックシノニムが作成されます。
▼パブリックシノニムを作成するSQL
CREATE PUBLIC SYNONYM dept FOR departments;
・シノニムはオブジェクトの別名を表すスキーマ・オブジェクトです。表やビューなどのオブジェクトに別名を付けることで、
オブジェクトの指定を簡単に行えるようになったり、スキーマ名を隠蔽してセキュリティを高めたりすることができます。
ただし、シノニムを使用するには、基となるオブジェクトに対する適切な権限が必要です。
例えば、表のシノニムを使用して問合せを行う場合は、基になる表に対する参照権限が必要です。
プライベートシノニムを作成するにはCREATE SYNONYM権限、パブリックシノニムを作成するにはCREATE PUBLIC SYNONYM権限が必要になります。
CREATE [PUBLIC] SYNONYM シノニム名 FOR オブジェクト名;
プライベートシノニムはスキーマと紐付けられますが、パブリックシノニムは特定のスキーマと紐付けられていないため、
プライベートシノニムとパブリックシノニムとで同名のシノニムを作成することができます。
プライベートシノニムとパブリックシノニムで同名のシノニムが存在する場合は、プライベートシノニムが優先されます。
■ビューについて
▼ビューを利用する目的は次の通りです。
・データへのアクセス制御
・複雑なSQL文の簡素化
・データの独立性を確保
・同じデータを異なる視点で表示
ビューとは、1つまたは複数の表や他のビューを基にして作成する仮想的な表のことです。ビューには実データは含まれません。
ビューに対する問合せを実行すると、Oracleサーバーは、ビューの基となっている実表へ問い合わせ処理を行います。
[データへのアクセス制御]
ビューに対するSELECT文では、ビューに定義されている列にしかアクセスできません。
表の一部の列の値をユーザーに参照させたくない場合などに、参照させたくない列を除いたビューを作成し、適切な権限を与えることで、データアクセスを制限することができます。
[複雑なSQL文の簡素化]
複数の表を結合して複雑な問合せを行う場合、予めその問合せでビューを作成しておくと、複雑な問合せを毎回行う必要はなく、ビューに対して問合せを行うことで、目的のデータを取り出すことが可能になります。
[データの独立性を確保]
ビューの基となっている実表の定義に変更があった後でも、ビューに定義されている列に変更がなければ、変更前と同様にビューにアクセスすることができます。
[同じデータを異なる視点で表示]
ある表からデータを取り出す場合、所属する部署や役職など、データを取り出すユーザーによって必要な情報が異なります。それぞれの視点でビューを作成しておくと、同じデータを異なる視点で表示できます。
ビューには、単一ビューと複合ビューの2種類のビューがあります。

■索引について
・表のデータへのアクセスを高速化する
・索引を設定している表ではROWIDを使用して検索する
・DML文実行時、索引がメンテナンスされる
索引はデータの検索を高速化するスキーマ・オブジェクトです。
表の列に索引が設定されると、索引が設定された列の値と、その物理的な格納場所(ROWID)を登録します。
索引が設定されていない表でデータを検索する場合、問合せの条件に従って、表の先頭のデータから1行ずつ検索していきますので、
データが大量にある場合には相当の時間がかかります。しかし索引を設定している表では、
ROWIDを使用してデータを検索するため、大量のデータの中からでも高速に目的のデータを探すことができます。
また、表に対してDML文を実行する度に、表に設定された索引はメンテナンス(必要であれば更新)されます。
・索引を設定している表を削除すると、設定されている索引は自動で削除されます。
・FOREIGN KEY制約定義時、自動的に制約は作成されません。PRIMARY KEY制約またはUNIQUE制約の定義時に一意索引が自動的に作成されます。
・UNIQUEオプションを指定すると一意索引が作成されます。
例)
CREATE UNIQUE INDEX ind
ON DEPARTMENTS(department_name);
▼索引を作成しないほうが良いとされます。
・WHERE句の条件としてあまり指定されない列
・規模が小さな表の列
・頻繁に更新、追加、削除される列
・式の一部として参照される列
▼索時のパフォーマンス向上につながるケース
・WHERE句の条件や結合条件としてよく使用される列
・列にNULL値が多く含まれており、NULL値以外の値を指定して検索する列
・表の規模か大きく、多くの問合せで2~4%未満の行を検索する列
■制約の定義について
・USER_CONS_COLUMNSビューは、ビューにアクセスするデータベースユーザーが所有していて、
制約が定義されている列を表示するデータ・ディクショナリ・ビューです。
・データ・ディクショナリ・ビューとは、データベース内のオブジェクトやユーザー、
権限などに関する様々な情報が格納されているが直接アクセスできないデータ・ディクショナリ表を参照するためのものです。
・ユーザーがアクセスできる、制約が定義されている全ての列を表示するのは、ALL_CONS_COLUMNSビュー
・ユーザー所有の表の制約を表示するのは、USER_CONSTRAINTSビュー
・ユーザーがアクセスできる表の制約を表示するのは、ALL_CONSTRAINTSビュー
■NOT EXISTS・NOT IN演算子について
・SQL文のNOT EXISTS演算子は、主問合せで取り出した1行が副問合せの条件を満たしていない場合、
つまり副問合せの結果が1行も返されない場合にTRUEとして評価され、主問合せの結果が返されます。
・SQL文のNOT IN演算子はリスト内の全ての値と等しくない場合にTRUEを返しますが、
副問合せの結果にNULL値が含まれていると全ての値と等しくないという判定がされません。
NOT IN演算子の場合は、リスト内の全ての値と等しくない場合にTRUEを返しますが、
NOT IN演算子の値のリストにNULL値が含まれていると、NULL値と比較対象の値の比較結果がNULL値になるので、
全ての値と等しくないという判定がなされません。そのため、主問合せではデータが1件も取り出されません。
■集合演算子について
[集合演算子の優先順位]
・集合演算子には優先順位はない
・1つのSQL文に複数の集合演算子が使用されている場合は、SQL文の先頭から順番に複合問合せが実行される
・優先順位を明示的に指定したい場合は、()括弧を用いて優先順位を指定する
■複合問合せについて
▼複合問合せにおいて、WHERE句、GROUP BY句、ORDER BY句等の使用は禁止されていません。
ただし、ORDER BY句を使用する場合には、以下のガイドラインに従います。
・ORDER BY句は複合問合せの最後の問合せに指定する
・ORDER BY句には最初の問合せに指定されている列名や列別名を指定する
・集合演算子は副問合せでも主問合せと同じように使用することができます。
・異なる表に対し集合演算子を使用することができる
集合演算子を用いた複合問合せでは、2つの問合せでSELECT句に指定する列や式の数を同数にしなければなりません。
また、2つの問合せでSELECT句に指定する列や式のデータ型も同じ、もしくは同じデータ型グループにしなければなりません。
ただし、データサイズは異なっていてもエラーとはなりません。
なお、同じデータ型グループとは同じデータを扱うデータ型をグループ化したものです。
例えば、CHAR型とVARCHAR2型はどちらも文字列を扱いますので、同じデータ型グループに分類されます。
▼集合演算子を用いて複合問合せを行う場合、SELECT句に指定する列や式は次のガイドラインに従います。
・複合問合せの列見出しは1つ目の問合せに指定された列名が使用される(それぞれの問合せで指定される列名が異なっていても良い)
・2つの問合せでSELECT句に指定する列や式の数を同数にしなければならない
・2つの問合せでSELECT句に指定する列や式のデータ型を同じ、もしくは同じデータ型グループにしなければならない
(ただし、データサイズは異なっていても良い)
・SELECT句に指定する列数が同じであれば、列名は異なっていても構いません。
・複合問合せの列見出しは1つ目の問合せに指定された列名が使用されます。
▼MINUS演算子を用いる
MINUS演算子を用いた複合問合せの結果は、1つ目の問合せ結果から2つ目の問合せ結果を引いた行を表示します。
そのため、1つ目の問合せと2つ目の問合せの順序を入れ替えた問合せでは結果が異なります。
その他の集合演算子では、順番を入れ替えても取り出される行は同じです。
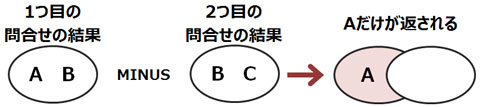
MINUS演算子による複合問合せでは、内部的に、問合せ結果をSELECT句の1番目に指定されている列の昇順に
ソートし(1番目に指定されている列に同値がある場合は、
さらに2つ目に指定されている列の昇順にソートします)、重複行を排除して結果を表示します。
なお、複合問合せでは問合せの結果にNULL値が含まれていてもNULL値を無視しません。
MINUS演算子での演算の結果にNULL値が含まれている場合、重複するNULL値は排除されます(NULL値が1つだけ表示されます)。
A表とB表それぞれにNULLがある場合、引き算されて、NULL行は出力しない結果となる。

▼UNION演算子を用いた複合問合せでは、2つの問合せの結果から重複行を排除して表示されます。
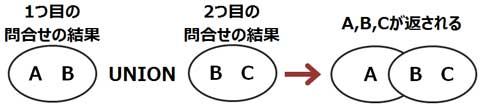
UNION演算子による複合問合せでは、内部的に、問合せ結果をSELECT句の1番目に指定されている列の昇順に
ソートし(1番目に指定されている列に同値がある場合は、さらに2つ目に指定されている列の昇順にソートします)、
重複行を排除して結果を表示します。
なお、複合問合せでは問合せの結果にNULL値が含まれていてもNULL値を無視しません。
UNION演算子での演算の結果にNULL値が含まれている場合、重複するNULL値は排除されます(NULL値が1つだけ表示されます)。
列数を同数にする必要がありますが、列名は異なっていても構いません。
▼INTERSECT演算子について
INTERSECT演算子を用いた複合問合せでは、2つの問合せの結果の共通する行を表示します。
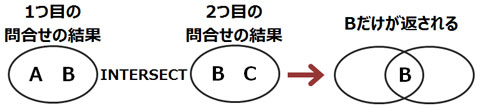
INTERSECT演算子による複合問合せでは、内部的に、問合せ結果をSELECT句の1番目に指定されている列の昇順に
ソートし(1番目に指定されている列に同値がある場合は、さらに2つ目に指定されている列の昇順にソートします)、
重複行を排除して結果を表示します。
なお、複合問合せでは問合せの結果にNULL値が含まれていてもNULL値を無視しません。
INTERSECT演算子での演算の結果にNULL値が含まれている場合、重複するNULL値は排除されます(NULL値が1つだけ表示されます)。
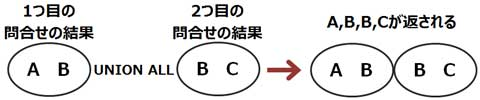
▼UNION ALLについて
UNION ALL演算子を用いた複合問合せでは、2つの問合せの結果を重複行も含めて表示します。
NULL値が含まれている場合は、重複したNULL値も全て表示します。
なお、問合せ結果は、UNION演算子を用いた複合問合せとは異なり、ソートされませんので注意しましょう。
複合問合せでは問合せの結果にNULL値が含まれていてもNULL値を無視しません。
UNION ALL演算子を用いた複合問合せでは、重複したNULL値も全て表示されます。
なお、UNION,INTERSECT,MINUS演算子では、問合せの結果がSELECT句の1番目に指定されている列で昇順にソートされますが、
UNION ALL演算子を用いた複合問合せでは、問合せの結果がソートされませんので注意しましょう。
▼集合演算子の優先順位について
集合演算子には優先順位はありません。1つのSQL文に複数の集合演算子が使用されている場合は、SQL文の先頭から順番に複合問合せが行われます。
優先順位を明示的に指定したい場合は、()括弧を用いて優先順位を指定します。
▼集合演算子を用いて複合問合せを行うには、いくつかのガイドラインがあります。
[SELECT句の指定]
・複合問合せの列見出しは1つ目の問合せに指定された列名が使用される(それぞれの問合せで指定される列名が異なっていても良い)
・2つの問合せでSELECT句に指定する列や式の数を同数にしなければならない
・2つの問合せでSELECT句に指定する列や式のデータ型を同じ、もしくは同じデータ型グループにしなければならない。
(ただし、データサイズは異なっていても良い)
※同じデータ型グループとは、CHAR型とVARCHAR2型のように文字同士など同じ種類のデータ型のことです。
▼集合演算子を用いて複合問合せを行う際にORDER BY句を指定する場合は、次のガイドラインに従います。
・ORDER BY句は複合問合せの最後の問合せに指定する
・ORDER BY句には最初の問合せに指定されている列名や列別名を指定する
※ORDER BY句で、列名または列別名と列番号は混在OK
■読取り一貫性について
複数のユーザーが同時に同じデータに対して操作を行うと、データの不整合が発生する可能性があります。
例えば、あるデータに対して、同時に、読取りを行うユーザーAと書込みを行うユーザーBがいる場合、
ユーザーAがデータの読取り中にユーザーBがデータの書込みを行ってしまうと、ユーザーAは一貫性のあるデータを
取得することができません。
このような場合、Oracle Databaseは「読取り一貫性」という機能でそれぞれのユーザーに対して一貫性のあるデータを提供します。
▼読取り一貫性は、データの読取りを開始した時点で最新のコミット済みのデータを返すことを保証します。
ユーザーAがデータの変更を行なっているとき、ユーザーAが変更処理をコミットするまで、
他のユーザーはユーザーAが変更後のデータを参照することはできません。
(ユーザーAは変更処理が確定されていなくても、変更後のデータを参照することができます)。
ユーザーAが変更処理をコミットする前に他のユーザーがそのデータを参照した場合、
他のユーザーへは変更前のデータが返されます。ユーザーAの変更が確定されるまで待機させられることはありません。
読取り一貫性を実現するために、Oracle DatabaseはUNDOセグメントという領域を使用します。
データの変更を行うと、変更前のデータがその領域にコピーされます。
読取り一貫性は、データの読取りを開始した時点で最新のコミット済みのデータを返すことを保証します。
データの変更処理がコミットされていない場合、変更したデータは変更したユーザーだけが参照でき、
他のユーザーへはUNDOセグメントにある変更前のデータが返されます。
・他のユーザーが更新中のデータを参照した場合、Oracleサーバーは更新前にコミットされたデータを返す
・読み取り一貫性を実現するためにUNDOセグメントが使用される
・未確定のデータは、更新中のユーザーだけが参照できる
■INSERTについて
表にデータを追加するには、INSERT文を使用します。
INSERT文にはデータを追加する列名と値を1対1で指定します。列名を省略する場合は、表内の列の構成の順で値を指定します。
列名と対応する値のデータ型が異なると、エラーとなります。
指定した列の個数とVALUES句に指定した値の個数が異なると、エラーとなります。
列名の指定が省略された場合、表内の列の構成と同じ順序で値を指定しなければなりません。
・INSERT句の列のリストを省略する場合、副問合せのSELECT句の列のリストには、
データを追加する表のすべての列を表の列構成の順番で指定しなければなりません。
・副問合せを使用したデータの追加では、INSERT文にVALUES句は指定しません。
・INSERT句の列のリストは省略可能です。
・副問合せにはWHERE句を指定することができます。
・INSERT文に副問合せを使用する場合、副問合せを囲む( )は必須ではありません。( )はあってもなくても構いません。
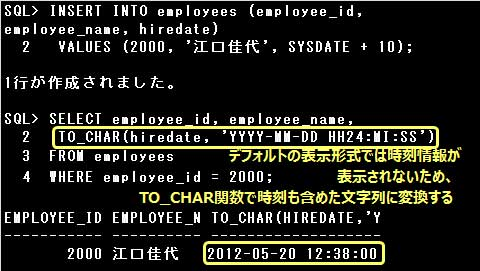
▼SYSDATE関数は現在の日時を表すDATE型の値を返します。またDATE型の値に数値を加算すると、日数として加算されます。
設問のSQL文では、SYSDATE関数が返すDATE型の値に10を加算していますので、
現在日時の2012年5月10日12時38分0秒に10日を加算した2012年5月20日12時38分0秒がHIREDATE列に登録されます。
例)
INSERT INTO employees (employee_id, employee_name, hiredate)
VALUES (2000, ‘江口佳代’, SYSDATE + 10);
1つの列の1行のみ返す副問合せは、INSERT文のVALUES句の中でも使用できます。
※注意点は、副問合せを用いる場合は、WHERE条件が一意に絞り込む、PRIMARY KEY制約が定義されていることが前提となる。
副問合せを使用してデータの追加を行うこともできます。
副問合せを使用したINSERT文では、VALUES句は使用できません。
INSERT句に指定する列のリストと、副問合せのSELECT句に指定する列のリストは同数かつ同じ順番で指定します。
また、INSERT句の列のリストは省略可能ですが、省略する場合、副問合せのSELECT句の列のリストには、
データを追加する表のすべての列を表の列構成の順番で指定しなければなりません
INSERT文でNOT NULL制約が定義されていない列を省略してもエラーとはなりません。省略した列にはNULL値が登録されます。
NOT NULL制約が定義されている列に対してNULL値を登録するまたは、省略することでNULL値が自動で登録されると、とエラーとなります。
■UPDATE について
UPDATE文のSET句で副問合せを使用して、表のデータを更新することができます。
SET句に副問合せを使用すると、別の表の値に基いてデータを更新することもできます。
・SET句に副問合せを指定してデータの更新を行うことができます。
・副問合せでは、主問合せと異なる表を参照することができます。
UPDATE文で列の値を更新する場合、更新する列に定義されている制約やデータ型を考慮する必要があります。
設問では、PRODID列にPRIMARY KEY制約が定義されているので、NULL値で更新したり複数の行で同じ値に更新することはできません。
また、制約が定義されていなくても、DATE型の列を数値や文字列で更新するなどデータ型が一致しない更新はできません。
UPDATE文では、SET句に更新する列名と値を=(イコール)でつなぎ指定します。
複数の列の値を1つのUPDATE文で更新する場合は、列名と値のセットを,(カンマ)で区切って指定します。
SET句に指定する列名と値のセットは同じデータ型でなければなりません。
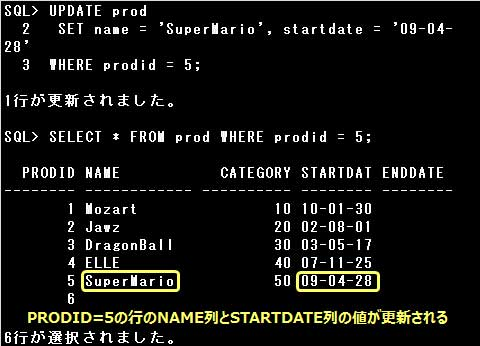
また、データの更新時は表に定義されている制約も考慮しなければなりません。
例えば、PRIMARY KEY(NULL値および重複値を許可しない)制約が定義されている列を、
NULL値で更新したり複数の行で同じ値に更新することはできません。
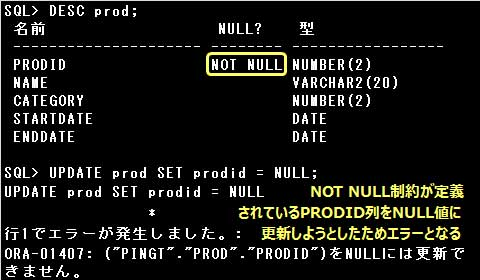
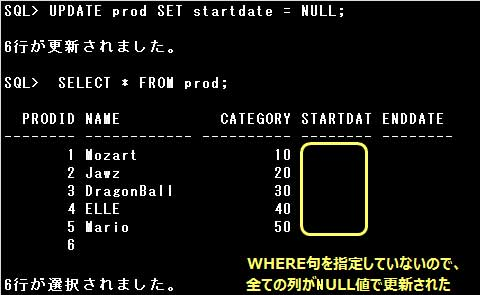
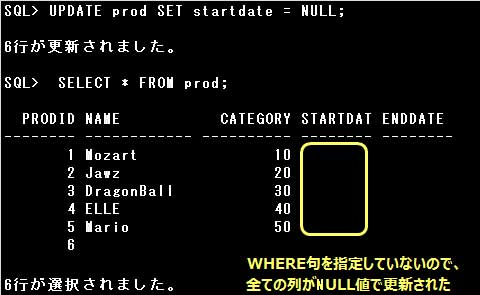
HERE句に条件を指定すると、条件に該当する行だけが更新されますが、
条件を指定しない場合は表の全ての行が更新されます。
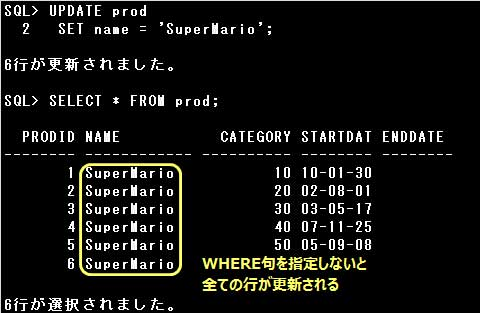
表のデータを更新するには、UPDATE文を使用します。
UPDATE文では、SET句に更新する列名と値を=(イコール)でつなぎ指定します。
複数の列の値を1つのUPDATE文で更新する場合は、列名と値のセットを,(カンマ)で区切って指定します。
なお、NOT NULL制約を定義された列をNULL値で更新することはできません。エラーとなります。
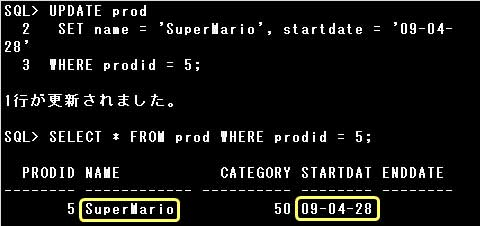
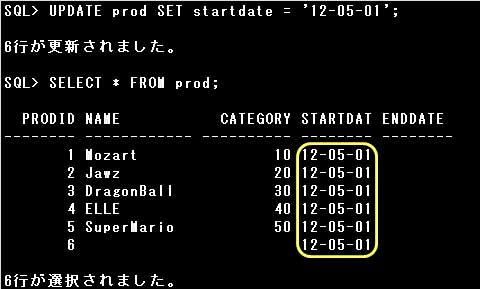
UPDATE文では、SET句に更新する列名と値を=(イコール)でつなぎ指定します。
複数の列の値を1つのUPDATE文で更新する場合は、列名と値のセットを,(カンマ)で区切って指定します。
SET句に指定する列名と値のセットは同じデータ型でなければなりません。
また、データの更新時は表に定義されている制約も考慮しなければなりません。
例えば、PRIMARY KEY(NULL値および重複値を許可しない)制約が定義されている列を、
NULL値で更新したり複数の行で同じ値に更新することはできません。

WHERE句に条件を指定すると、条件に該当する行だけが更新されますが、条件を指定しない場合は表の全ての行が更新されます。

表名の代わりに副問合せを指定したUPDATE文では、副問合せのSELECT句に指定した列しか更新することができません。
また、表名の代わりに副問合せを指定したUPDATE文にWHERE句を指定する場合も、
副問合せのSELECT句に指定した列に関する条件しか指定できませんので注意しましょう。
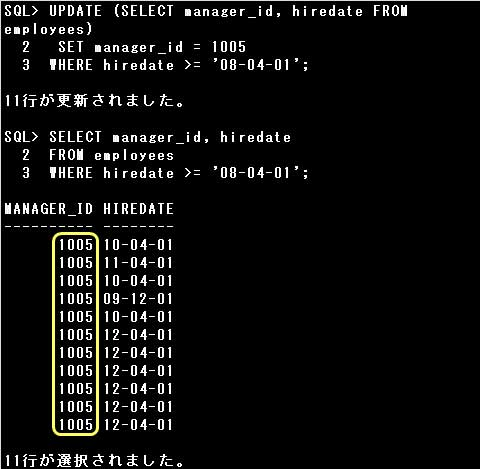
▼例)
・UPDATE (SELECT manager_id, hiredate FROM employees) SET manager_id = 1005 WHERE hiredate >= ’08-04-01′;
表名の代わりに副問合せを指定したUPDATE文です。更新する列、
WHERE句の条件に指定した列ともに副問合せのSELECT句に指定されている列ですので、エラーにはならず、期待通りに更新されます。
▼エラー例)
・UPDATE (SELECT manager_id FROM employees) SET manager_id = 1005 WHERE hiredate >= ’08-04-01′;
表名の代わりに副問合せを指定したUPDATE文です。
WHERE句に指定したHIREDATE列が、副問合せのSELECT句に指定されていませんので、エラーとなります。
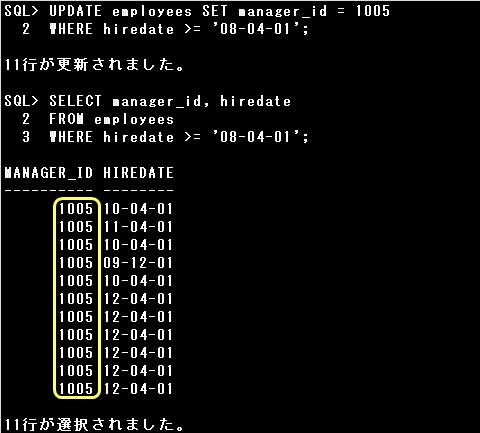
▼例)
・UPDATE employees SET manager_id = 1005 WHERE hiredate >= ’08-04-01′;
更新する値や条件に誤りがありませんので、エラーにはならず、期待通りに更新されます。
■排他ロックについて
・Oracle Databaseは複数のユーザーが同時に同じ行に対して変更処理(INSERT,UPDATE,DELETE)を行った場合に、
データの矛盾が生じないよう、行毎に排他ロックをかけて変更処理を行います。
・排他ロックがかかっている行に対して変更処理を行おうとすると、排他ロックが解除されるまで待機させられます。
排他ロックはトランザクションの終了時に解除されます。
・更新中のデータを他のユーザーが参照した場合、UNDOセグメントにコピーされた変更前のデータが返されます。
・排他ロックでは、行毎にロックされます。
排他ロックはトランザクションの終了時まで解除されません。
したがって、ユーザーAの変更処理により排他ロックがかかっている行を、ユーザーBが変更しようとすると、
ユーザーAの変更処理がコミットもしくはロールバック等でトランザクションが終了するまで、
ユーザーBは待機しなければなりません。
排他ロックの動作は次の通りです。
1.ユーザーBがPROD表にPRODID列の値が「11」,NAME列の値が「Debussy」であるデータを1件追加します
2.ユーザーBが追加処理をコミットします
3.ユーザーAがPROD表のPRODID=11の行のNAME列の値を「Liszt」に変更します。
この時、PROD表のPRODID=11の行に排他ロックがかかり、解除されるまでは他のユーザーがこの行を変更することはできません。
4.ユーザーBがPROD表のPRODID=11の行のNAME列の値を「Debussy」に変更します。
しかし、ユーザーAの3.の操作で排他ロックがかかっているため、排他ロックが解除されるまでユーザーBは待機します。
5.ユーザーAがPROD表のPRODID=11の行のNAME列を参照すると、「Liszt」が返されます。
6.ユーザーAが変更処理をコミットします。PROD表のPRODID=11の行にかけられていた排他ロックが解除されます。
7.PROD表のPRODID=11の行の排他ロックが解除されたので、待機中のユーザBの変更処理が実施されます。
8.ユーザーBがPROD表のPRODID=11の行のNAME列を参照すると、「Debussy」が返されます。
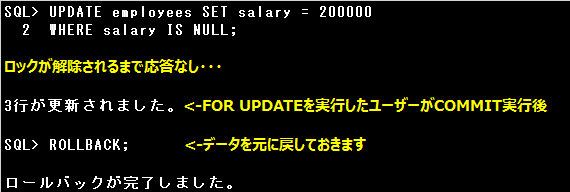
SELECT文にFOR UPDATE句を指定すると、SELECT文で取り出される行に排他ロックをかけることができます。ロックがかかっていても、
他のユーザーは該当の行を検索できますが、更新や削除はできません。
他のユーザーが該当の行に更新などのSQL文を発行すると、FOR UPDATE句を使用したユーザーがCOMMIT文やROLLBACK文、
またはDDL文やDCL文を発行してトランザクションを終了するまで待機させられます。
また、設問のSQL文のようにFROM句に複数の表が指定されている場合は、それぞれの表の対象となる行にロックをかけます。
SQL*Plusの別のセッションから、EMPLOYEES表の該当行を更新するUPDATE文を発行すると、そのまま待機させられます。
FOR UPDATE句を実行したユーザーがトランザクションを終了してロックが解除されると、更新できました。
別のセッションから、DEPARTMENTS表の該当行を更新するUPDATE文を発行すると、
ロック中は上記と同様にそのまま待機させられます。ロックが解除されると、更新できました。

別のセッションから、FOR UPDATE句のSELECT文に該当しない行を更新するUPDATE文を発行すると、ロック中でも問題なく更新できます。
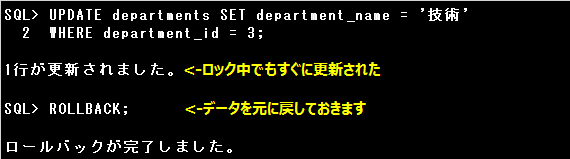
SELECT文にFOR UPDATE句を指定すると、SELECT文で取り出される行に排他ロックをかけることができます。
この時、SELECT文で取り出される行が別のセッションで既にロックされていると、別のセッションのロックが解除されるまで、
SELECT文は待機しますが、NOWAITオプションを指定すると、待機せずにすぐにエラーを返します。
設問のSELECT文では、FOR UPDATE句にNOWAITオプションが指定されているので、SELECT文で取り出される行が既に
別のセッションで排他ロックをかけられている場合は、待機せずにエラーを返します。
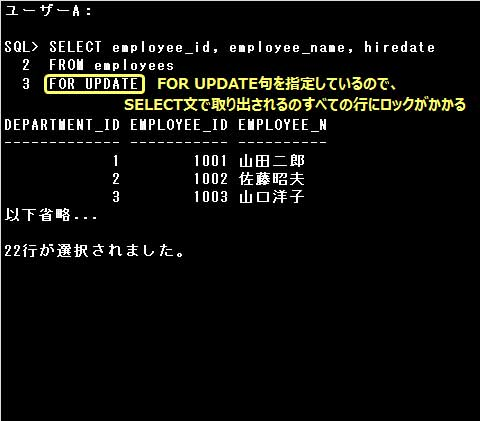
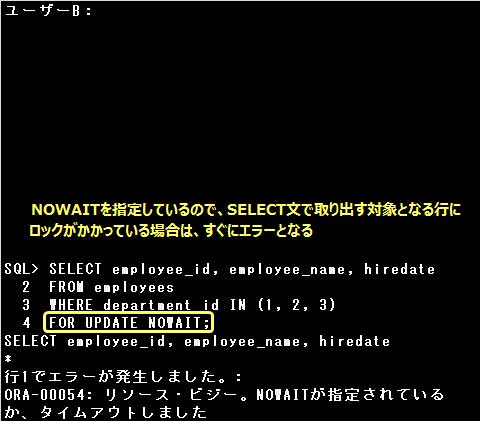
▼排他ロック、排他制御の処理
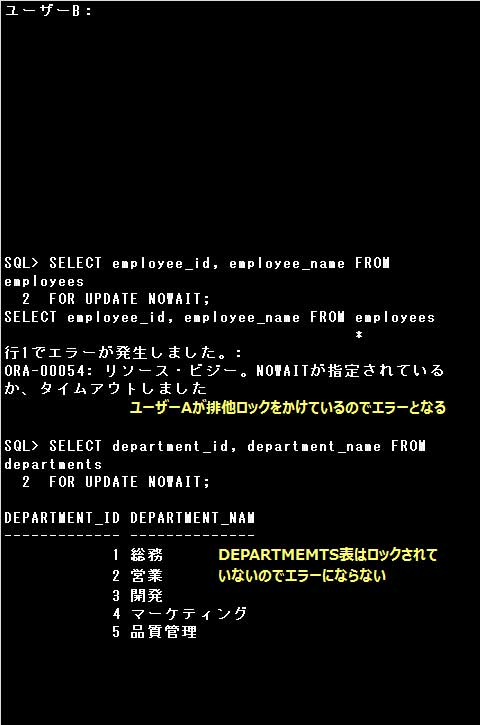
ユーザーA:
SQL> SELECT d.department_name, e.employee_name
2 FROM departments d JOIN employees e USING (department_id)
3 FOR UPDATE OF e.employee_name NOWAIT; … ①
ユーザーB:
SQL> SELECT employee_id, employee_name FROM employees
2 FOR UPDATE NOWAIT; … ②
SQL> SELECT department_id, department_name FROM departments
2 FOR UPDATE NOWAIT; … ③
ユーザーA:
SQL> UPDATE employees SET salary = 350000 WHERE employee_id = 1020;
SQL> COMMIT;
①:SELECT文のFOR UPDATE句に OF 表名.列名 オプションが指定されています。EMPLOYEES表のEMPLOYEE_NAMEが含まれる行にのみ排他ロックがかけられます。
②:①でユーザーAが排他ロックをかけているため、ユーザーBはSELECT文にFOR UPDATE句を指定しても排他ロックをかけることはできません。さらにNOWAITオプションを指定しているので、SELECT文実行後、直ちにエラーとなります。
③:DEPARTMENTS表には排他ロックはかけられていないので、検索後該当する行が表示されます、
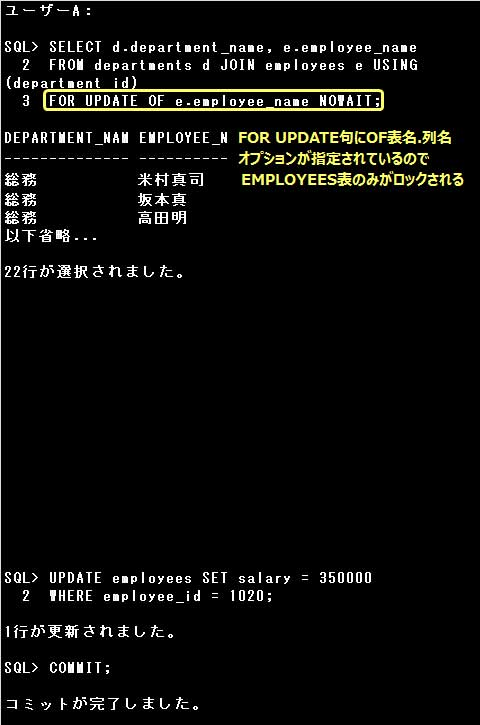
ユーザーAが変更処理を行うと、変更対象となる行は排他ロックがかけられ、他のユーザーが変更処理を行おうとすると、
ユーザーAの変更処理が確定されるまで待機しなければなりません。
また、変更処理中のデータを他のユーザーが参照すると、他のユーザーは変更処理が確定されるまで、
変更後のデータを参照することはできません。
・ユーザーAが10.で参照したデータのNAME列の値は”Chopin”である
・ユーザーBの5.の操作は待機させられる
■トランザクションについて
・全てのセーブポイントは破棄される。
・すべての処理が確定または破棄され、取消すことはできない。
・書込み処理をした行はロックが解除され、他のユーザーは変更したデータを参照できる。
トランザクションはCOMMIT文やROLLBACK文実行時やDDL文、DCL文実行時に終了します。
CREATE文は、DDL文に該当しますが、SELECT文、UPDATE文は、DML文です。
また、SAVEPOINT文ではトランザクション内にマーカーを作成しますが、トランザクションは終了しません。
▼トランザクションは次のトランザクション制御文を使用して明示的に制御することができます。

トランザクションは、前回処理を確定または取消した後に、COMMIT文やROLLBACK文を実行した時や、DDL文、DCL文を実行した時に終了します。
DML文は1つ以上の文のまとまりで1つのトランザクションになりますので、一連の処理の終了後、
COMMIT文またはROLLBACK文を実行する等してトランザクションを終了します。
・トランザクションはDDL文により終了する
・トランザクションはDCL文により終了する
・トランザクションは前回コミットまたはロールバックしてから次回コミットまたはロールバックするまでの一連の処理のことである
・DML文は1つ以上の文のまとまりで1つのトランザクションになります。
・SAVEPOINT文はトランザクション内にマーカーを作成します。SAVEPOINT文ではトランザクションは終了しません。
■DELETEについて
表のデータを削除するには、DELETE文を使用します。
ある条件に合致したデータだけを削除する場合は、DELETE文にWHERE句を指定して削除する行の条件を指定します。
例)
DELETE FROM prod WHERE startdate >= ’03-04-01′;
TRUNCATE文は削除するデータの条件を指定することができません。WHERE句を指定するとエラーとなります。
FROMキーワードは省略することができます。
また、WHERE句に条件を指定すると条件に該当する行だけが削除されますが、条件を指定しない場合は表の全ての行が削除されます。
なお、DELETE文では、副問合せを使用することができます。
副問合せは、WHERE句で条件を指定する場合と、削除の対象となる表を表名の代わりに副問合せで指定する場合に使用することができます。
▼[副問合せで条件を指定する場合]
条件に副問合せを使用すると、異なる表のデータに基いてデータを削除することもできます。
例)
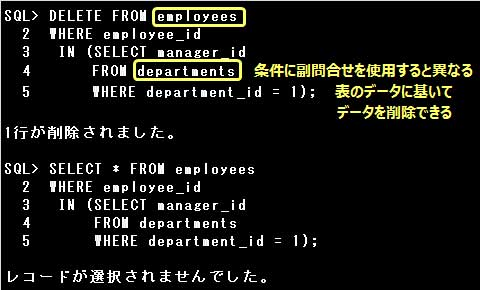
DELETE FROM employees
WHERE employee_id
IN (SELECT manager_id
FROM departments
WHERE department_id = 1);
▼[表名の代わりに副問合せを指定する場合]
DELETE文では、表名の代わりに副問合せを指定することができます。
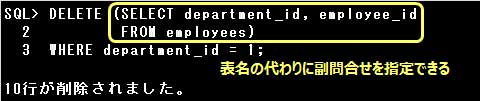
ただし、WHERE句で削除する行の条件を指定する場合、条件には副問合せで指定した列のみ使用することができます。
表の全てのデータを削除するには、DELETE文を削除する行の条件を指定せずに実行するか、TRUNCATE文を実行します。
DELETE文のFROMキーワードは省略が可能です。
例)
・TRUNCATE TABLE prod;
・DELETE FROM prod;
・DELETE prod;
TRUNCATE文は表の全てのデータを削除します。WHERE句を指定して条件に合致するデータだけを削除することはできません。
WHERE句を指定すると、エラーとなります。
DELETE文でWHERE句を指定すると、指定した条件に合致するデータだけを削除します。


▼[副問合せで条件を指定する場合]
条件に副問合せを使用すると、異なる表のデータに基いてデータを削除することもできます。
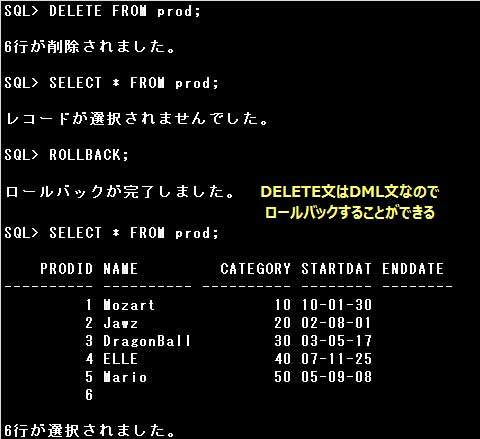
DELETE文は表のデータを削除しますが、表の構造は削除しません。
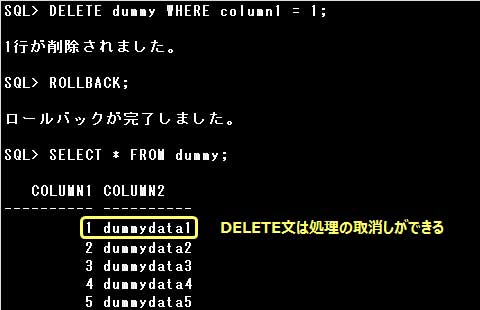
また、DELETE文はDML文ですので、COMMIT文で操作が確定されるまではROLLBACK文で操作の取消しが可能です。
DELETE文では、削除の対象となる表を指定する際、表名だけではなく副問合せによる指定をすることができます。
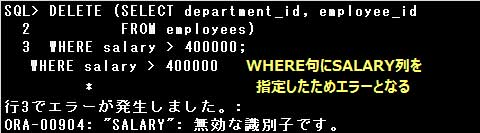
表名の代わりに副問合せを指定したDELETE文では、条件に副問合せで指定した列のみ使用することができます。
設問のSQL文は文では、副問合せにDEPARTMENT_ID列とEMPLOYEE_ID列が指定されていますが、
WHERE句で副問合せに指定されていないSALARY列を使用しているため、エラーとなります。
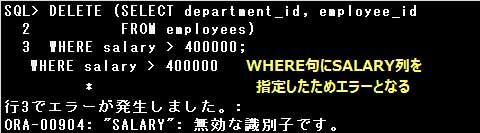
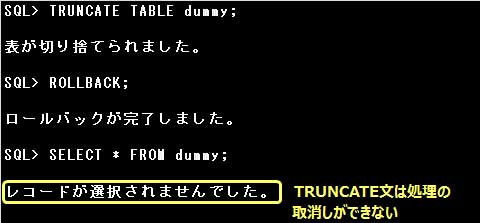
■TRUNCATEについて
・削除するデータを指定できない
DELETE文ではWHERE句に削除するデータの条件を指定して実行することができますが、
TRUNCATE文は削除するデータの条件を指定することができません。WHERE句を指定するとエラーとなります。
■TRUNCATEについて
・削除するデータを指定できない
DELETE文ではWHERE句に削除するデータの条件を指定して実行することができますが、
TRUNCATE文は削除するデータの条件を指定することができません。WHERE句を指定するとエラーとなります。
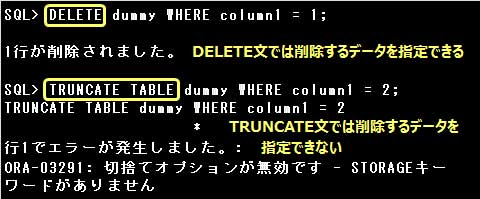
・DDL文のため自動コミットが実行される
DELETE文はDML文ですので、DELETE文実行後、処理を確定する前にROLLBACK文を実行すると
データの削除を取消すことができますが、TRUNCATE文はDDL文であるため、
TRUNCATE文の実行後に自動的に処理が確定され取消すことができません。
・DELETE文よりも処理が高速である
TRUNCATE文では処理の取消しができず、ロールバック用のデータを生成する必要がないため、
DELETE文よりも高速にデータを削除することができます。
・削除トリガーは起動しない
TRUNCATE文実行時、表に定義された削除トリガー(DELETE文で表のデータが削除された時に
自動的に起動するプログラム)は実行されません。削除トリガーはDELETE文でデータを削除した時に実行されます。
TRUNCATE文では表のデータを削除しますが、索引は削除されません。
■ROLLBACKについて
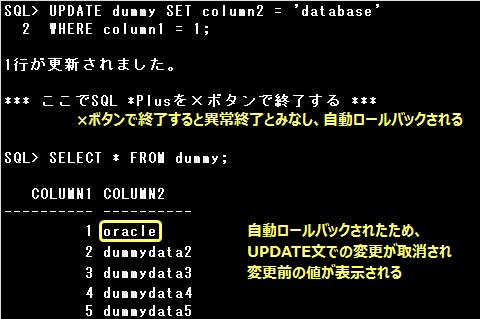
▼Oracle Databaseでは次の場合に自動ロールバックされます。
・システム障害が発生した場合
・SQL *Plusを×ボタンで終了した時など異常終了した場合
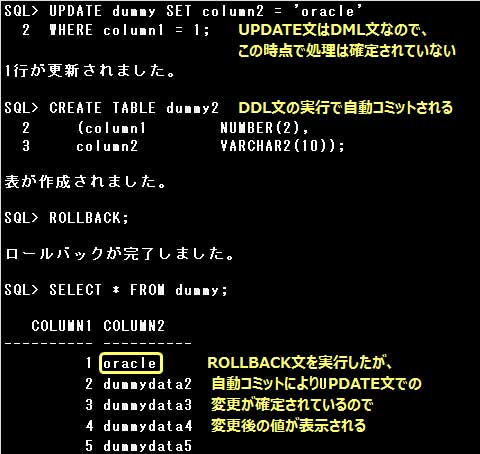
▼自動コミットの場合
・EXIT文でSQL *Plus終了時
・DDL文実行時
・SAVEPOINT文実行時
SAVEPOINT文ではトランザクション内にマーカーを作成しますが、トランザクションは終了しません。

▼[自動コミット]
▼[自動ロールバック]
トランザクション中にセーブポイントを作成し、ROLLBACK文を実行することで、セーブポイントから現在までの処理を取消すことができます。
セーブポイントの作成と処理の取消しは次のように行います。
[セーブポイントの作成]
SAVEPOINT セーブポイント名;
[処理の取消し]
ROLLBACK; または
ROLLBACK TO [SAVEPOINT] セーブポイント名;
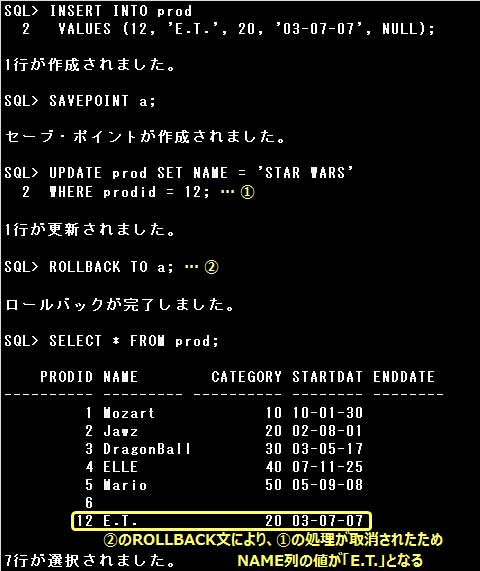
セーブポイント名を指定せずにROLLBACK文を実行すると、トランザクション全体が取消され、
トランザクションは終了します。
以下の例では最初のINSERT文も取消されます。

TO SAVEPOINT句を指定してROLLBACK文を実行すると、指定されたセーブポイントより後に実行された処理が取消されます。
表のデータの操作のほか、指定されたセーブポイント以降に作成したセーブポイントも破棄されます。
ただし、トランザクションは終了しません。そのため、トランザクション中のセーブポイント以前の処理は取消されません。

■MERGEについて
MERGE文は異なる表の行をマージできるDML文です。
1つのMERGE文で、該当する行があればUPDATE、無ければINSERTというように、行の挿入と更新を同時に行えます。
■DMLについて
データ操作言語(DML)文は、スキーマ・オブジェクトのデータにアクセスし変更や削除などの操作を行えますが、
オブジェクトの構造は変更しません。
SQL文の種類は次のとおりです。DML文の実行ではトランザクションは終了しません。

■ROLLBACK TO SAVEPOINTについて
1.INSERT文により、PROD表にデータが1件追加します。
ただし、INSERT文はDML文に該当し自動コミットされないため、データの追加は確定されていない状態です。
2.セーブポイントaを作成します。
3.UPDATE文により、PROD表のPRODIDが11であるデータのNAME列の値を’Chopin’に変更します。
ただし、UPDATE文はDML文に該当し自動コミットされないため、データの変更は確定されていない状態です。
4.セーブポイントaより後に実行した処理を取消します。この場合、3.のUPDATE文が取消されます。
5.DELETE文により、PROD表のPRODIDが11であるデータを削除します。これは1.で追加したデータです。
6.COMMIT文により、それまでの処理が確定されます。
したがって、PROD表のPRODIDが11である行の削除は確定され、セーブポイントaも破棄されます。
7.セーブポイントaは既に破棄されているので、エラーとなります。
6.のCOMMIT文により、トランザクション内の処理が確定され、作成したセーブポイントはすべて破棄されます。
したがって、7.でROLLBACK TO SAVEPOINT文を実行した時にはセーブポイントaは破棄されているのでエラーとなります。

■相関副問合せについて
設問のSQL文では、主問合せの各行に対してその都度、副問合せが実行される「相関副問合せ」が使用されています。
副問合せの中でそのFROM句に無い表を参照する場合(副問合せの外側にある表を参照する場合)に、相関副問合せとして処理されます。
EMPLOYEES表 e から取り出した各従業員のSALARY列とCOMMISSION列を、副問合せで取り出した、その従業員の上司と同じ金額に更新します。
副問合せは複数の列を返す「複数列副問合せ」を使用しています。

■表の削除
DROP TABLE文で表をごみ箱に移動したり、完全に削除したりすることができます。ごみ箱に移動した表は復元することができます。
表を削除すると、表と表内のデータ、表に定義した制約、索引も同時に削除されます。その表を参照している
ビューやシノニムは削除されませんが、無効になります。無効になったビューやシノニムにアクセスするとエラーになります。
以上より、
・表を削除すると、表に定義されている制約や索引も同時に削除される
・ごみ箱に移動した表を復元することができる
・表の削除はDROP ANY TABLE権限を持つ全てのユーザーが表を削除することができます。
・表を完全に削除するにはPURGEオプションを指定して削除します。
・表を削除すると、制約や索引は同時に削除されますが、関連するビューやシノニムは削除されません。
表を削除すると、表と表内のデータ、表に定義した制約、索引も同時に削除されます。
その表を参照しているビューやシノニムは削除されませんが、無効になります。
無効になったビューやシノニムにアクセスするとエラーになります。
PURGEオプションを付けずに表を削除すると、表はごみ箱に移動するだけで、完全に削除されるわけではありません。
完全に削除するにはPURGEオプションを指定して表を削除します。
■CHECK制約について
CHECK制約の条件にはWHERE句に指定する条件と同等のものを指定できますが、次の指定はできません。
・CURRVAL,NEXTVAL,LEVEL,ROWNUM疑似列
・SYSDATE,UID,USER,USERENV関数
・他の行を参照する問合せ
また、複数の列を使用する条件は表レベルで定義しなければなりません。
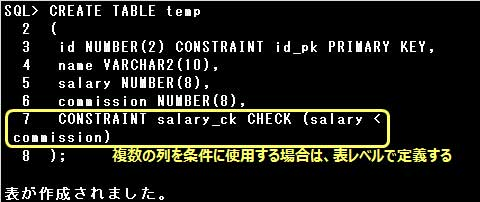
列にCHECK制約を定義すると、定義された列には条件に合致した値またはNULL値しか登録できなくなります。
CHECK制約は次のように定義します。
CONSTRAINT 制約名 CHECK (条件)
▼例)
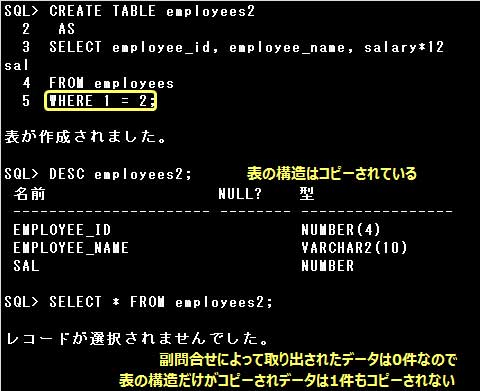
CREATE TABLE employees2
AS
SELECT employee_id, employee_name, salary*12 sal
FROM employees
WHERE 1 = 2;
副問合せによる表の作成では、表作成時に、副問合せで取り出されたデータも一緒にコピーされますが、
副問合せの結果取り出されるデータが1件もなかった場合は表の構造だけがコピーされます。
設問の副問合せのWHERE句に指定された条件は、1 = 2と絶対に成立しない条件ですので、
副問合せによって取り出されるデータは0件です。したがって、設問のSQL文では表の構造だけがコピーされます。
■CREATEについて
副問合せによる表の作成では、表作成時に、副問合せで取り出されたデータも一緒にコピーされますが、
副問合せの結果取り出されるデータが1件もなかった場合は表の構造だけがコピーされます。
設問の副問合せのWHERE句に指定された条件は、1 = 2と絶対に成立しない条件ですので、
副問合せによって取り出されるデータは0件です。
したがって、設問のSQL文では表の構造だけがコピーされます。
CREATE TABLE文と副問合せを使用して、既存の表から新しい表を作成することができます。
この時、表構造をコピーして新しい表を作成するだけでなく、副問合せで取り出したデータも同時にコピーすることができます。
副問合せを使用して新しい表を作成するには、次のように記述します。
CREATE TABLE 表名[(列名 [, 列名 …])]
AS
副問合せ
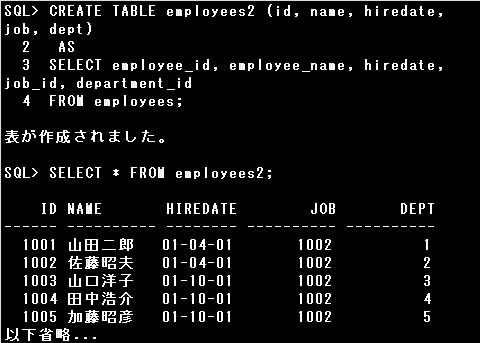
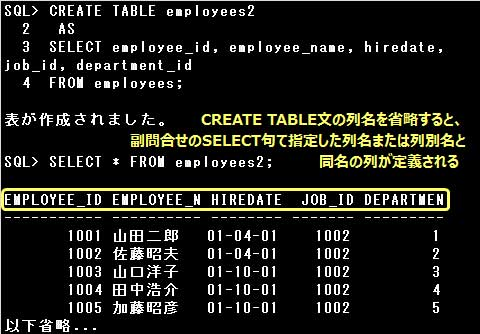
CREATE TABLE文に指定する列名の数と、副問合せのSELECT句に指定する列名(列別名)の数は、同数にしなければなりません。
CREATE TABLE文の列名を省略すると、副問合せのSELECT句に指定された列名または列別名と同名の列が定義されます。
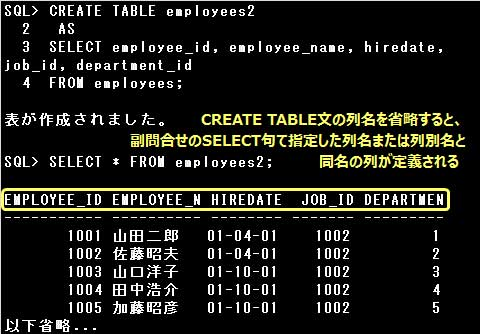
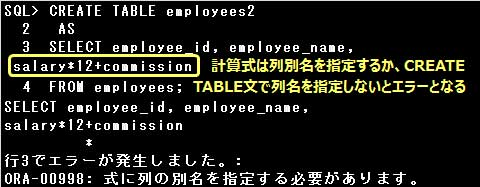
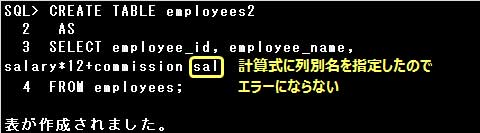
なお、副問合せのSELECT句に計算式や関数を指定する場合は、計算式や関数に列別名を指定するか、
CREATE TABLE文で列名を指定しなければなりません。
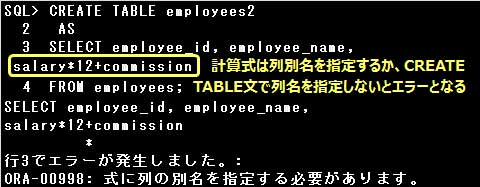
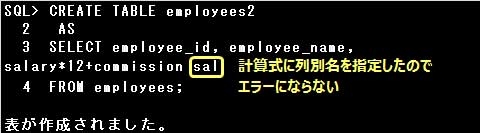
また、副問合せによる表の作成では、制約やデフォルト値に関する次の規則があります。
[データ型の指定はできない]
データ型は副問合せのSELECT句に指定した列のデータ型、または式の値のデータ型から自動的に定義されるため、
CREATE TABLE文にデータ型を指定するとエラーとなります。

[デフォルト値を設定できる]
副問合せによる表の作成時、新たに作成する表にデフォルト値を設定できます。

[制約を定義できる]
副問合せによる表の作成時、新たに作成する表に制約を定義することができます。
[NOT NULL制約のみ引継がれる]
列に定義されているデフォルト値や制約のうち、明示的に定義されたNOT NULL制約だけが、
副問合せによって新たに作成された表にコピーされます。
PRIMARY KEY制約、UNIQUE制約、FOREGIN KEY制約、CHECK制約、デフォルト値はコピーされません。

オブジェクト名は以下の命名規則に従う必要があります。
・オブジェクト名は30バイト以下
・使用できる文字は、0~9,A~Z,a~z(日本語環境の場合は漢字,ひらがな,カタカナも使用可)
・使用できる記号は、_,$,#のみ
・オブジェクト名の先頭の文字は、数字,記号以外の文字
・Oracleの予約語は使用できない
この他、同一スキーマ内では重複するオブジェクト名は使用できません。また、アルファベットの大文字と小文字は区別されません。
参考:
データベースに格納できる表やビューなどを総称してデータベース・オブジェクトと言います。
データベース・オブジェクトは必ずいずれかのユーザーに所有されており、スキーマ・オブジェクトとも呼ばれます。
主なスキーマ・オブジェクトは以下のとおりです。

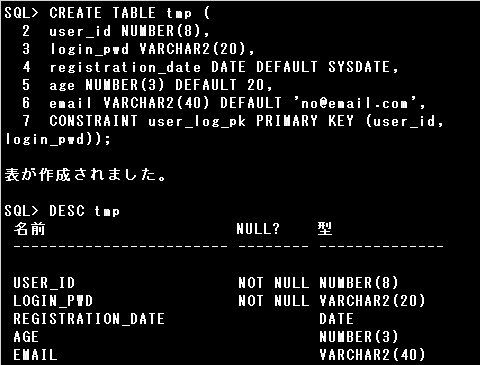
▼列追加
ALTER TABLE prod3
ADD status VARCHAR2(20) DEFAULT ‘FOR SALE’ NOT NULL;
ALTER TABLE文で、既存の表へ新しい列を追加できます。
ALTER TABLE 表名 ADD
( 列名 データ型(サイズ) [DEFAULT 値] [[CONSTRAINT 制約名] 制約タイプ]
[, 列名 データ型(サイズ)] …
);
表に既存のデータが存在する場合、新しく追加された列にはデフォルトでNULL値が設定されます。表が空でない場合、
NOT NULL制約を定義した列を追加しようとするとエラーとなりますが、列の追加時にNULL以外のデフォルト値を指定することで、
既存のデータの列にもデフォルト値が設定されます。
設問のSQL文では、追加するSTATUS列にNOT NULL制約とデフォルト値「FOR SALE」を指定しているため、正常に列が追加され、
既存の行のSTATUS列にデフォルト値が設定されます。
NOT NULL制約と共にデフォルト値を指定すれば、表が空でなくてもNOT NULL制約の列を追加できます。
1つの列を追加する場合は、ADDの後の括弧()は省略できます。
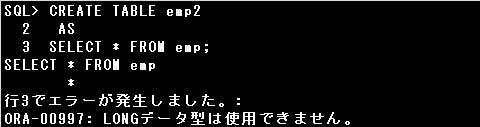
▼LONG型には以下の制限があります。
・LONG型の列は1つの表に1つだけ定義できる
・LONG型の列には制約は定義できない(NULLおよびNOT NULL制約を除く)
・LONG型の列はGROUP BY句とORDER BY句に指定できない
・副問合せによる表の作成時、LONG型の列はコピーできない
したがって、EMP表のNOTE列をGROUP BY句やORDER BY句に指定することはできません。
また、EMP表をコピーして新しい表を作成する際に、副問合せのSELECT句にNOTE列が含まれているとエラーとなります。
ORDER BY句にNOTE列が指定されているのでエラーとなります。

GROUP BY句にNOTE列が指定されているのでエラーとなります。

副問合せにNOTE列が含まれているのでエラーとなります。
列のデフォルト値は「列名 データ型 DEFAULT 値」の書式で記述します。等号=は不要なのでエラーとなる。
NOT NULL制約は列レベルでしか定義できません。表レベルで定義は不可である。
PRIMARY KEY制約を定義すると、定義された列または列の組合せに重複したデータやNULL値を登録できなくなります。
複数の列の組合せにUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。
1つの列に複数の列レベル制約を定義する場合はスペースで区切りますが、「,」で区切っているのでエラーとなります。

列の組合せに対してPRIMARY KEY制約を定義する場合は、表レベルで定義しなければなりません。
また、CHECK制約はWHERE句で指定できる条件と同様の指定ができますが、SYSDATE関数を使用できない等いくつかの制限があります。
CHECK制約の条件にはWHERE句で指定できる条件と同様の指定ができます。BETWEEN演算子も使用することができます。
FOREIGN KEY制約は列レベル、表レベルのどちらでも定義することができます。
列の組合せに対してFOREIGN KEY制約を定義する場合は、表レベルで定義します。
VARCHAR2型の列データを定義する場合、データ長を必ず定義しなければなりません。
なお、NUMBER型ではデータ長の指定を省略することができます。

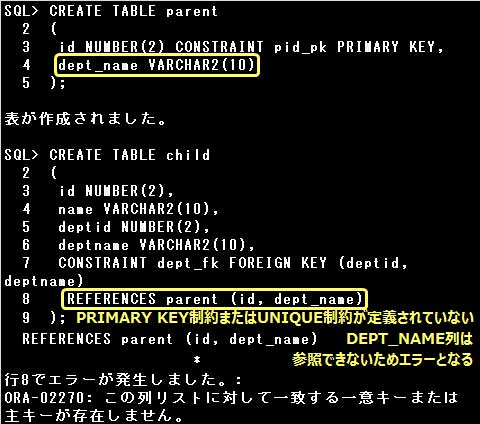
▼FOREIGN KEY制約で参照できる親表の列は、PRIMARY KEY制約またはUNIQUE制約が定義されている列だけです。
FOREIGN KEY制約の参照先にPRIMARY KEY制約またはUNIQUE制約が定義されていない列を指定するとエラーとなります。
副問合せによる表の作成時、新たに作成する表の列にデータ型を指定することができません。列のデータ型は副問合せにより自動的に定義されます。
また、副問合せで問合せを行なっている表の列にNOT NULL制約が明示的に定義されている場合、
新たに作成する表にもNOT NULL制約がコピーされますが、その他の制約はコピーされません。
■制約について
制約は列レベル、表レベルで定義することができます。制約を定義する場合は、次の事項に注意します。
・CONSTRAINT 制約名は省略することができる
・CONSTRAINT 制約名を省略した場合は、「SYS_Cn」という制約名となる(nには一意の番号が振られる)
・1つの列に複数の列レベル制約を定義する場合は、スペースで区切って定義する
例) 列名 データ型 [[CONSTRAINT 制約名1] 制約の種類] [[CONSTRAINT 制約名2] 制約の種類]
・1つの表に複数の表レベル制約を定義する場合は、カンマで区切って定義する
・列レベル制約と表レベル制約では機能に違いはない
・列レベル制約と表レベル制約は1つの表で同時に指定できる
・複数の列の組み合わせに対して制約を定義する場合は、表レベル制約でのみ定義できる
・NOT NULL制約は列レベルでのみ定義できる
なお、PRIMARY KEY制約は1つの表に1つだけしか定義することはできません。
また、CHECK制約の条件にはSYSDATE関数を使用することはできません。
▼エラー例)
CREATE TABLE table1
(
cust_id NUMBER(2) CONSTRAINT cid_pk PRIMARY KEY,
order_id NUMBER(2) CONSTRAINT oid_pk PRIMARY KEY,
qty NUMBER(2) CONSTRAINT qty_ck CHECK (qty BETWEEN 1 AND 20)
);
PRIMARY KEY制約は1つの表に1つしか定義できません。
複数の列の組合せに対してPRIMARY KEY制約を定義する場合は、表レベルで定義します。
▼エラー例)
・CREATE TABLE table1
(cust_id NUMBER(2) CONSTRAINT cid_pk PRIMARY KEY,
order_id NUMBER(2),
order_date DATE CONSTRAINT date_ck CHECK (order_date < SYSDATE)
);
CHECK制約の条件にはWHERE句に指定する条件と同等のものを指定できますが、いくつかの制限がありSYSDATE関数を使用することはできません。
▼エラー例)
・CREATE TABLE table1
(
cust_id NUMBER(2) UNIQUE, NOT NULL,
order_id NUMBER(2),
qty NUMBER(2) CONSTRAINT qty_ck CHECK (qty BETWEEN 1 AND 20)
);
1つの列に2つ以上の制約を定義する場合は、,(カンマ)で区切るのではなく、スペースで区切ります。
副問合せによる表の作成時、データ型とNOT NULL制約は問合せた表から新たに作成する表へとコピーされますが、
NOT NULL制約以外の制約やデフォルト値はコピーされません。
ただし、副問合せによる表の作成時にデフォルト値を設定したり、制約を定義することはできます。
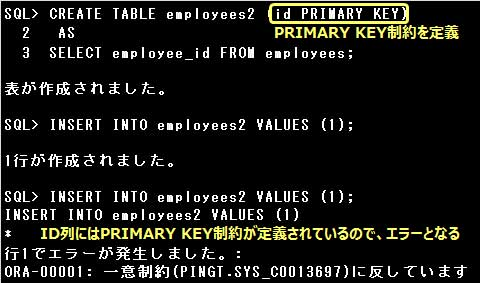
・表が作成されるが、ID列にはPRIMARY KEY制約は定義されない
・副問合せによる表の作成時、列のデフォルト値を設定したり、制約を定義したりすることができます。
参考:
CREATE TABLE文と副問合せを使用して、既存の表から新しい表を作成することができます。
この時、表構造をコピーして新しい表を作成するだけでなく、
副問合せで取り出したデータも同時にコピーすることができます。
副問合せを使用して新しい表を作成するには、次のように記述します。
CREATE TABLE 表名[(列名 [, 列名 …])]
AS
副問合せ

CREATE TABLE文に指定する列名の数と、副問合せのSELECT句に指定する列名(列別名)の数は、同数にしなければなりません。
CREATE TABLE文の列名を省略すると、副問合せのSELECT句に指定された列名または列別名と同名の列が定義されます。
なお、副問合せのSELECT句に計算式や関数を指定する場合は、計算式や関数に列別名を指定するか、CREATE TABLE文で列名を指定しなければなりません
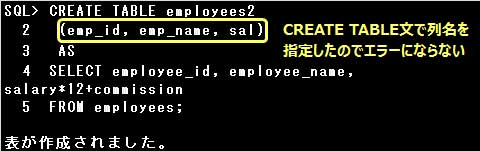
▼副問合せによる表の作成では、制約やデフォルト値に関する次の規則があります。
[データ型の指定はできない]
データ型は副問合せのSELECT句に指定した列のデータ型、または式の値のデータ型から自動的に定義されるため、
CREATE TABLE文にデータ型を指定するとエラーとなります。
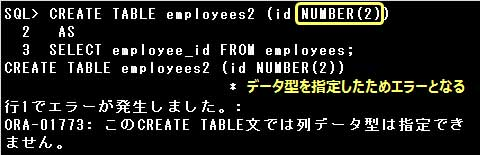
[デフォルト値を設定できる]
副問合せによる表の作成時、新たに作成する表にデフォルト値を設定できます。
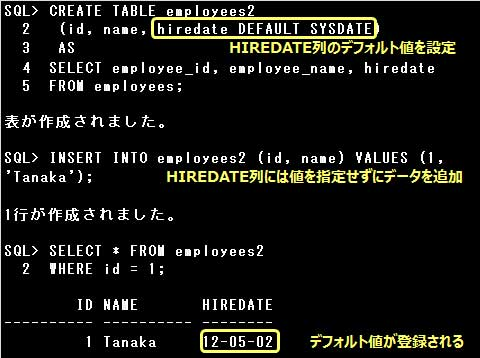
[制約を定義できる]
副問合せによる表の作成時、新たに作成する表に制約を定義することができます。
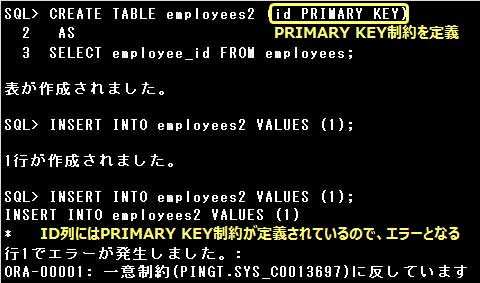
[NOT NULL制約のみ引継がれる]
列に定義されているデフォルト値や制約のうち、明示的に定義されたNOT NULL制約だけが、
副問合せによって新たに作成された表にコピーされます。
PRIMARY KEY制約、UNIQUE制約、FOREGIN KEY制約、CHECK制約、デフォルト値はコピーされません。
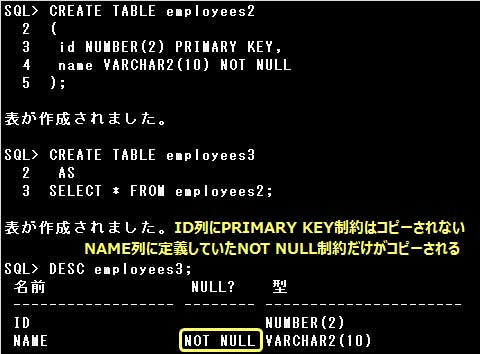
副問合せによる表の作成では、副問合せのSELECT句に計算式や関数を指定する場合は、
計算式や関数に列別名を指定するか、CREATE TABLE文で列名を指定しなければなりません。
計算式や関数に列別名が指定されておらず、かつCREATE TABLE文の列名も省略されているとエラーとなります。
Oracle Databaseでは、制約を列レベル、表レベルで定義することができます。
また、1つの列に1つまたは複数の制約を定義することができます。
複数の列の組み合わせに対して制約を定義することもできますが、その場合は、表レベルで定義しなければなりません。
なお、NOT NULL制約は列レベルでしか定義できません。
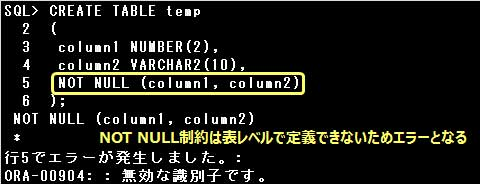
▼NOT NULL制約
NOT NULL制約は列レベルでしか定義することができません。
設問のSQL文では、表レベルでNOT NULL制約を定義しているため、エラーとなります。
制約名は省略することができます。制約名を省略した場合は、「SYS_Cn」という制約名となります。
表にPRIMARY KEY制約は必ずしも定義する必要はありません。
NOT NULL制約が定義できる列のデータ型に制限はありません。表レベルでのNOT NULL制約は定義できません
▼UNIQUE制約
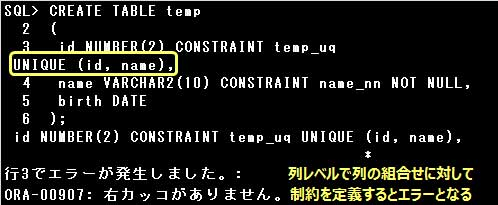
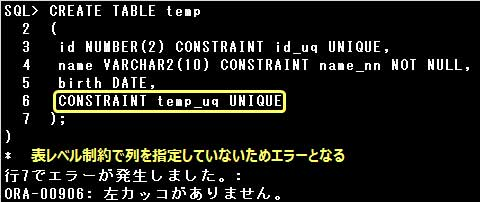
UNIQUE制約は列レベル、表レベルのどちらでも定義することができますが、
複数の列の組合せに対してUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。
また、表レベルで制約を定義する場合は、制約を定義する列を指定しなければなりません。
列または列の組合せにUNIQUE制約を定義すると、定義された列または列の組合せに重複したデータを登録することができなくなります。
ただし、NULL値は登録することができ、複数の行にNULL値を登録する事もできます。

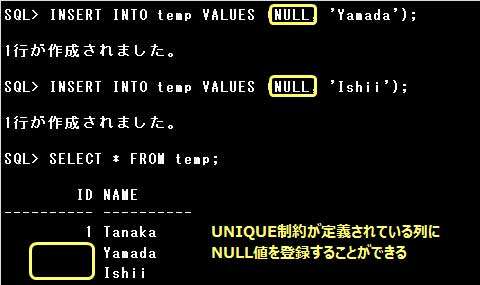
複数の列の組合せに対してUNIQUE制約を定義する場合は、表レベルで定義しなければなりません。
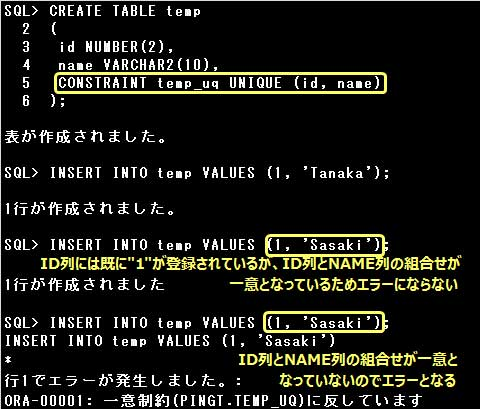
▼PRIMARY KEY制約を後から付ける場合
EMPLOYEES2表のEMP_ID列には重複した値のデータが登録されています。
PRIMARY KEY制約が定義された列には重複したデータやNULL値は格納できませんので、
EMP_ID列にはPRIMARY KEY制約を定義することはできません。
既にデータが登録されている表に後から制約を追加する事はできますが、
登録されているデータが追加する制約の条件を満たしている必要がありますので注意して下さい。

▼Oracle Databaseでは、次の制約を定義することができます。
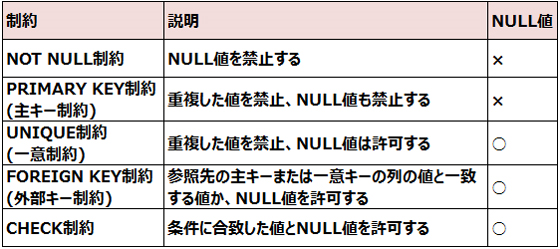
PRIMARY KEY制約では、NULL値を格納できないのに対し、
UNIQUE制約やFOREIGN KEY制約では制約を定義した列にNULL値を格納することができます。
CHECK制約に指定できる条件にはいくつかの制限があります。CURRVAL,NEXTVAL,LEVEL,ROWNUM疑似列の参照はできません。
NOT NULL制約は列レベルでしか定義することができません。
▼FOREIGN KEY制約
FOREIGN KEY制約の親表に指定された表は、依存する行の有無にかかわらず削除することができません。
また、親表のデータを削除した場合の子表の振る舞いは、
・ON DELETE CASCADEオプション
・ON DELETE SET NULLオプション
を指定して設定できます。
ON DELETE CASCADEでは、親表の行が削除された場合、参照していた子表の行も同時に削除されます。
また、ON DELETE SET NULLでは、親表の行が削除された場合、参照していた子表の列にNULL値を設定します。
制約とは、表に格納するデータに関するルールです。表に制約を定義することで、ルールに反するデータの追加や、
ルールを満たさなくなるようなデータの更新、削除を行うことができなくなります。
制約のチェックのために時間が必要となるため、パフォーマンスは向上しません。
但し、一部の制約には索引を自動作成するものがあり、索引はデータ参照時のパフォーマンスを向上させる効果があります。
しかしそれは索引の効果であり、制約それ自体がパフォーマンスを向上させる訳ではありません。
制約は表に格納するデータに関するルールです。表自体のアクセスを宣言するものではありません。表へのAccess制限を制約では不可能である。
FOREIGN KEY制約で参照できる親表の列は、PRIMARY KEY制約またはUNIQUE制約が定義されている列だけです。
FOREIGN KEY制約の参照先にPRIMARY KEY制約またはUNIQUE制約が定義されていない列を指定するとエラーとなります。