■デカルト積
▼結合条件が指定されていないデカルト積(Oracle結合構文)
SELECT * FROM EMP, DEPT;
▼CROSS JOIN句によるクロス結合
SELECT * FROM EMP CROSS JOIN DEPT;

等価結合と非等価結合では、結合条件に一致する行だけが結合されて戻される。
外部結合は、結合条件に一致しない行も結合せずに戻す。
▼Oracle結合構文の外部結合
結合条件に一致しない行も結果として、戻される。
一方の表からすべての行を取り出し、他方の表から結合条件に一致する行を結合する。
一致しななければ結合せずに、値が欠落したまま行が戻される。
外部結合演算子+を使う。条件の一致しない行のある表の方に指定する。
すべての行が取り出されない。データが欠落している表の方に指定する。
データが欠落する表の方に外部結合演算子を付ける。
外部結合演算子は、どちらか一方の表にだけ指定する。
外部結合で、すべての行を取り出すのはどちらの表か?、値が欠落するのはどちらの表か?の2点を見る。
値の欠落する方の表に外部結合演算子+を付ける。
DDL(データ定義)文の種類は、
CREATE TABLE
DROP TABLE
REVOKE
ALTER TABLE
GRANT
TRUNCATE


その表を親表とするOREIGN KEY制約を定義するためには、REFERENCESオブジェクト権限が必要である。
FOREIGN KEY制約の親キー列を削除はできない。CASCADE CONSTRAINTSキーワードを指定すると削除できる。
ON DELETE CASCADEオプションは、特定の親キー値(行)を削除するための機能である。列の削除はできない。

既存の行に、NOT NULL制約を付けることはできない。だが、デフォルト値を指定すれば追加できる。
■SQL関数の入れ子(ネスト)の深さについては、単一行関数は、制限なし、グループ関数は第2レベルまで。
DECODEは、どの条件値とも一致しない時は、デフォルト値(省略時はNULL)を戻す。
FM修飾子
fmDD 3
DD 03
fmを付けることで、先行ゼロが回避される。
デフォルト日付書式以外で日付データを入力する場合は、TO_DATE関数を使う。
セーブポイントまでロールバックしただけでは、トランザクションは終了しません。
ロールバックで削除されたセーブポイントは、再度セーブポイントとして設定できる。
スキーマオブジェクトは、
表
ビュー
索引
順序
シノニム
データベースリンク
■SELECT文のFOR UPDATE句
検索するデータを排他ロックし、SELECT文で検索した後にその大元の表のデータを他のセッションから更新するのを防ぐ。
排他ロックをかけないと、検索したデータと実際の表のデータが異なることになり、直後の更新作業が表とな異なる間違ったデータに基づくものとなり、
不正な結果をもたらすことになる。
列レベルと表レベルのどちらでも制約を定義できるのは外部キーである。
■FOREIGN KEY制約における親キーの削除ルールについて

■期間リテラル
期間データ型
INTERVAL YEAR(桁数) TO MONTHのリテラル
期間データは、12ヶ月以上は、年換算となる。
例えば、100ヶ月の場合は、年換算で8年と4ヶ月となり、8-4で表される。
INTERVAL DAY(桁数) TO SECOND(桁数)のリテラル
期間データは、24時間以上を日数に、60分以上は時間に、60秒以上は分に換算される。
例えば、25時間であれば、1日1時間となる。

■SQL行制限
ORDER BY句が指定され、WITH TIES指定は有効のとき、
カウント3番までスキップして、カウント4番目から数えて、カウント7番目までを抽出する。
WITH TIES指定がある場合は、同値がカウント7番目で複数あった場合は、同値分全てを抽出する。
例えば、カウント7番目で同値が3つあれば、カウント9番目まで出力となる。
よって、抽出される行のカウント数は、9行となる。

■DESCRIBEコマンド
DESCRIBEコマンドを使い、表またはビューの列構造を表示で入る。表示される情報は下記の通り。
列名
列のデータ型
NULL値を許すかどうかの情報(空白または、NOT NULL)
■TO_DATE関数
TO_DATE関数で文字データを日付データに明示的データ型変換できる。
HIDATE = TO_DATE(’10-03-16′)
だた、TO_DATE関数で日付書式を省略しているので、デフォルト日付書式DD-MON-RRで文字データを解析する。
03が数値で、日付書式は月の名前の省略形(例えば、JAN,MAY)などのため、エラーと成る。
ENAME = 3000
文字型に、数値をセットすると、暗黙的に文字データが’3000’に変換されるので、エラーにならない。
■DROP TABLE PURGE句
表はゴミ箱へは移されず、すぐに削除され、索引も同時に削除される。
削除されると、表および索引が使用していた領域は解放され、他のオブジェクトで再利用可能となる。
順序は、一意な番号を生成するオブジェクトで、表の主キー値の生成などに使われる。
順序は、表に依存しない。順序を使って、主キーを生成した表を削除しても、順序は残る。
■論理演算子NOT
NOTは、直後の条件の結果を反転させる。
直後の条件式を否定形で書き換えることで、NOTを外した、よりわかりやすい条件式にすることができる。
NOT(A AND B) -> NOT(A) OR NOT(B)
NOT(A OR B) -> NOT(A) AND NOT(B)
NOT(SAL BETWEEN 2000 AND 3000) -> SAL NOT BETWEEN 2000 AND 3000
NOT(HIREDATE >- ’01-APR-81′) -> HIREDATE < ’01-APR-81′
■日付型へ文字列をセットする
TO_CHAR(’01-JANUARY-1981′)は、デフォルト日付DD-MON-RRに則って、解析され、暗黙的にDATE型に変換される。
解析で、MONの代わりにMONTH、RRの代わりにRRRRが自動的に試行されて、エラーにはならない。
この逆も自動的に試行される。
TO_CHAR(2000,’$999,99′) 2000 ー> $2000.00となり、$が変換できずエラーと成る。
SAL NUMBER(7,2)
■1つの列を削除する時は、DROP COLUMN句を使う。
複数列を削除する場合は、DROP句を使う。
■列に多くの値が含まれている場合は、削除に時間がかかるため、SET UNUSEDを使い、列を未使用化しておき、システムの負荷が低いときなどに
DROP UNUSED COLUMNS句で未使用列を削除すると、パフォーマンスへの悪影響を回避できる。
■DROP句または、DROP COLUMN句で列を明示して削除すると、存在する未使用列(UNUSED)も同時に削除される。
■CASCADE CONSTRAINTSオプションを使用すれば、親キーを削除できる。
■TRIM関数
省略時のデフォルトは、BOTH
TRIM(0 FROM 1000) は、0文字を切捨てるので、1が戻る。
TRIMは、文字を切り捨てる。文字列は扱わない。
TRIM(‘OR’ FROM ‘ACLE’)は、文字列を切捨てようとしているので、エラー
■HAVING句
HAVING句では、グループ関数のネストは使用できないため、エラーと成る。
例)
HAVING MAX(COUNT(*))
WHERE句では、グループ関数を使えない。
■NOT EXISTS演算子
相関副問合せで、AとBのデータを比較して、比較して所属のないデータを抽出する。
■FOREIGN KEY制約の親キーの削除ルール
親キーの削除ルールのデフォルトは、削除制限であり、外部キーから参照されている親キーを削除できない。
オプションの
ON DELETE CASCADE
ON DELETE SET NULL
を使用することで外部キーから参照されている親キーを削除できる。
■LIKE演算子を使ったワイルドカード検索について
パーセント記号%やアンダースコアを使い、ワイルドカード検索を行える。 %やを、文字リテラルとして、検索する場合には、エスケープ文字ESCAPEを使用する。
エスケープ文字ESCAPEの次の%や_は、ワイルドカード文字ではなく、文字リテラルとして扱われる。
エスケープ文字として、Eを使うと、条件式は下記の通りとなる。
例)er_を含む文字列を検索する時、
CUSTNAME LIKE ‘%erE_%’ ESCAPE ‘E’
■SUM関数
SUM関数およびAVG関数は、引数として数値データ型の他に暗黙的に数値データ型に変換可能な数値以外のデータ型を取ることができる。
例えば、文字型’1234’を暗黙的に数値データ型に型変換して、取り扱う。
COUNT(*)は、NULL値を含む全行数を取り出す。
UNIQUEは、DISTINCTと等価であり、列の重複した行とNULL値の行を除いた行数を戻す。

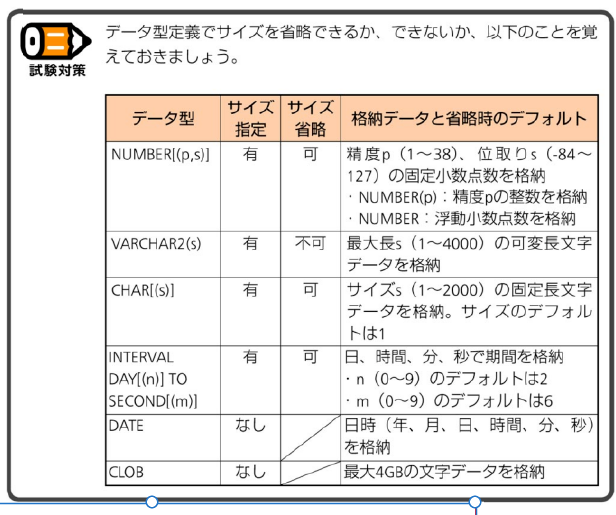
▼VARCHAR2は、データ型定義でサイズ指定を省略できない。
■NVL関数
NVL関数の2つの引数のデータ型が、異なる場合、2番目の引数のデータ型が1番目の引数のデータ型に暗黙的変換がされる。
だが、2番目の引数が文字列で、1番目の引数が数値だと、文字列を数値に変換できず、エラーと成る。そのため、1番目の引数をTO_CHAR型変換する必要がある。
■NVL2関数
NVL2関数の2番目と3番目の引数のデータ型が異なる場合、3番目の引数のデータ型を、2番めのデータ型に暗黙的変換がされる。
2番目が数値型、3番目が文字型だと、2番目をTO_CHAR型変換する必要がある。
■LPAD https://sql-oracle.com/?p=725
LPAD(文字列,桁数,埋める文字列)
文字列の左側から指定桁数分、埋めていく。
SELECT LPAD(‘A123’,6) ROM DUAL
指定した文字列を左から6桁になるまで、空白を埋める。
結果)[ A123]
■RPAD
RPAD(文字列,桁数,埋める文字列)
文字列の右側から指定桁数分、埋めていく。
SELECT RPAD(‘A123′,6,’0’) FROM DUAL;
6桁になるまで右側をゼロ埋めする。
結果)A12300
■ORDER BY句によるソート
昇順でソートした場合、デフォルトでは、NULLは、最後に表示される。
降順でソートした場合、デフォルトでは、NULLは、最初に表示される。
ORDER BY SAL NULL LAST
明示的に指定して、最後の行に表示させる。
NULL値は、大小関係においては、無限大を意味する。ゆえに昇順表示では、最大値は最後の行に表示となる。
降順表示では、最大値から表示されるので、NULLは、最初の行に表示される。
昇順は、階段を1段、2段、3段~と上がっていくので、小さな値が最初の行に表示される。
降順は、階段を一番高いところから、下がっていくので、大きな値が最初の行に表示される。
■CASE式
CASE式では、すべての戻り値は、同じデータ型でなければならない。異なる場合は、エラーと成る。
エラー例)
SELECT CASE WHEN COMM IS NULL THEN ‘ZEN’ ELSE COMM END FROM EMP;
THEN 文字列 ELSE 数値型 ENDのため、データ型不一致のため、エラーと成る。
■COALESCE関数
すべての引数は同じデータ型でなければならない。
異なる場合は、エラーと成る。
エラー例)
SELECT COALESCE(COMM, ‘NO DATE’) FROM EMP;
■DECODE関数 https://oreno-it.info/archives/3188
DECODE関数の戻り値のデータ型が異なる場合、先頭の戻り地のデータ型に他の戻り地が暗黙的に変換される。
変換できない場合は、エラーと成る。
例)検索値を1つだけ指定した場合
SELECT DECODE(COMM,NULL,’NO DATE’,COMM) FROM EMP;
DECODE(列名,値1,結果1,結果2)
指定した列名の値が、指定した値1の時、結果1を出す。値1でない場合は、結果2を出す。
例)検索値を2つ指定した場合
SELECT(COLL,0,’不合格’,1,’合格’,’対象外’);
DECODE(列名,値1,結果1,値2,結果2,結果3)
例)NULL値を置換する
DECODE(COLL,NULL,’未受験’,1,’受験’,’対象外’)
■FOREIGN KEY制約における親キー削除
外部キーで使用されている親キー値の行削除はできない。
▼削除するための方法
●外部キーを削除する。
外部キーで使用されえいない親キー値の行は削除できるので、解除したい親キー値が外部キーとして使用されていない状態を作る。
削除したい親キー値を外部キーとして、持つ行を削除すれば、親キー値も削除できるようになる。
●FOREIGN KEY制約による関連付けの削除
FOREIGN KEY制約を削除したり、または、FOREIGN KEY制約を無効化したりすることで、関連付けをなくせば、親キーを削除できる。
●ON DELETE CASCADEまたは、ON DELETE SET NULLオプション
外部キーで使用されている親キーはデフォルトではあS駆除制限されているため、削除できない。
だが、FOREIGN KEY制約にオプションを設定することで、DELETE文およびTRUNCATE TABLE 表名 CASCADE文で削除可能と成る。
■ORDER BY句
ORDER BY句では、列名、式、列別名、SELECT句の列リストの順番を指定できる。
ASC(昇順)、DESC(降順)、NULLS FIRST、NULLS LASTを指定できる。

■TO_CHAR関数
G(桁区切り)、D(ピリオド)を使い文字列に変換できる。
例)
TO_CHAR(KINGAKU,’999G999D99′)
■TO_TIMESTAMP関数
TIMESTAMP型のデータは、TO_DATE関数で変換できないので、エラーと成る。
TO_TIMESTAMP関数を使う必要がある。
■副問合せを使用した表の作成ガイドライン
副問合せでは、データ型は、指定できない。元の表からコピーされる。
制約では、NOT NULL制約のみ継承される。
副問合せの中で、式を指定できる。ただし、列名あるいは列別名を指定する必要がある。
表の定義の列数と副問合せの列数は一致させなければならない。
■IN演算子とOR演算子の比較
IN演算子とOR演算子は、処理速度は、同じパフォーマンスとなる。
IN演算子を使用するメリットは、条件式の論理性、わかりやすさの向上にある。
■GROUP BY句と他の句(SELECT句、ORDER BY句)との指定項目の一致
SELECT句とGROUP BY句。GROUP BY句とORDER BY句には、同じものを指定する必要がある。
■SQL * PlusおよびSQL Developerの機能である置換変数について
置換変数は、&シングルアンパサンド、&&ダブルアンパサンドの2種類がある。
初回だけ入力は、&&を使う。
■リレーショナルデータベース管理システムについて
リレーショナル・データベース(RDB)には次のような特徴があります。
・データを行と列からなる2次元の表形式で格納する
・関連のあるデータをグループ化し、複数の表に分割して管理する
・関連のある表同士を表に格納されたデータに基づいて関連付けることができる
・E. F. Coddのルール(エドガー・F・コッドによって考案されたRDBMSに関する規則)をサポートする
・SQLを使用してデータにアクセスする
オブジェクト・リレーショナル型データベースは、オブジェクト指向データベース(OODB)とも呼びます。次の特徴があります。
・リレーショナル型データベースの機能を拡張し、完全な互換性を持つ
・データ構造が定義されたメソッドが組み込まれている
・同じデータベースで複数のオブジェクトをサポートする
[第1正規形(1NF)]
第1正規化は、非正規形の表に次の作業を行います。
・主キーを設定する
・繰り返し現れる列のデータをグループ化して、別の表に切り離す
・導出項目(他の属性から算出できる項目)を削除する
・第2正規形
第2正規化は、第1正規形の表から部分関数従属性であるものを除きます。
・第3正規形
第3正規化は、第2正規形から推移関数従属性を除きます。
【正規化】
正規化とは、データの重複を排除し、データ間の正しいリレーションシップを設定してデータを一元管理できるようにすることです。正規化はリレーショナル・データベースの設計において重要な作業です。
正規化には第1正規化から第5正規化がありますが、ほとんどの場合は第3正規化まで行えば、実務上は問題ないとされています。
正規化されたものを正規形といいます。ここでは第3正規形までの正規化を解説します。
[非正規形]
非正規形は正規化されていないデータです。
例えば、以下の受注伝票のようなデータは非正規形です。この受注伝票を正規化していきましょう。
[第2正規形(2NF)]
第2正規化は、第1正規形の表から部分関数従属性であるものを除きます。
まず、関数従属性とは「ある属性(列)の値Xが決まると、別の属性の値Yが自動的に決まる」ことです。この場合「X → Y」と表記し、YはXに関数従属するといいます。
部分関数従属性は、YがXの一部に関数従属することです。第2正規化は、この部分関数従属性を除き、主キー列の値が決まれば主キー以外の列の値が決まるような表に分割します。つまり、複合主キーの一部の列の値から導き出せる列があれば、それらを別の表に分割するということです。
[第3正規形(3NF)]
第3正規化は、第2正規形から推移関数従属性を除きます。
推移関数従属性とは、「Xが決まるとYが決まり、Yが決まるとZが決まる」という関係です。
X → Y、 Y → Z、但しY → Xは不成立の場合、「X → Z」と表記し、ZはXに推移関数従属であるといいます。
上記の条件の表記は、それぞれ
X → Y : 主キーと、主キー以外の列(非キー属性)の関数従属性
Y → Z : 非キー属性間の関数従属性
を表しています。
「X → Y」の部分は、第2正規化で完全関数従属性まで整理しているので、この部分の作業は不要です。残る非キー属性間の関数従属性「Y → Z」を除く作業が、第3正規化の推移関数従属性を除くということになります。つまり、主キー以外の列が相互に依存関係を持たないようにします。
SELECT文の検索結果から重複した行を排除するには、SELECTキーワードの直後に1度だけDISTINCTキーワードを指定します。
DISTINCTキーワードに続けて複数の項目を指定した場合は、指定した項目の組合せで重複を排除した行が表示されます。
・SELECT DISTINCT(*) FROM sales;
・SELECT DISTINCT (prod_id, cust_id) FROM sales;
DISTINCTキーワードの後の項目を()括弧で囲むとエラーになります。
除算と乗算の優先順位は同じです。同じ優先順位の演算子が複数使われている場合は、左側の計算から順番に行われます。
